序
这是csapp系列的第五篇文章。具体题目请见官网。本文主要讲csapp中的architecture lab的流程和心得。如果有什么写得不好的地方,欢迎联系我修改(右下角小图标点开即可对话)。
同样的,在正式开始实验之前,建议先把官方的资料看一遍,保证对实验需要做什么,怎么做有一定的了解。总体来说,本实验在不追求满分的情况下,还是很容易通过的。主要难度都是在part C上,尤其要优化到高分十分困难,笔者最后的得分为56.3/60.0,仅供参考。
architecture lab 实验要求
这个实验总共分为三个部分,part A, part B, part C。其中,第一部分要求我们将三个用C写的函数翻译成y86-64指令,第二部分要求我们往seq ISA中添加一个新的指令iaddq。第三个部分给了我们一个ncopy的函数和一个pipeline的hcl文件,要求我尽可能地加快程序运行的速度。结果是用CPE(cycles per element)来衡量。达到9.0即算实验通过,7.5为满分。
实验文件(主要用到的在三个文件夹当中)
misc:part A 需要用到的文件夹
seq: part B 所在文件夹
pipe:part C 所在文件夹
实验目的
- 加深对CPU的指令集架构的了解,理解pipeline的基本实现原理
- 理解hardware和software之间的基本联系。简单了解它们之间是如何配合协作的
- 掌握一些程序优化的简单方法
y86-64 模拟器的配置
个人认为,这个应该是本实验最麻烦的一个点了。花了很长的时间,出了各种bug,下面进行安装过程进行简单的介绍。
所用系统为:arch-linux。不同版本对同一个问题的解决方法可能不太一样,但大体上有相似之处,下面仅供参考
tcl/tk
如果不想安装GUI界面的同学可以忽略此步
首先,本实验比较老,需要用到的tcl/tk版本号为8.5,8.6以上的版本没办法正常使用。然而,现在直接下载默认的应该是8.6版本的,因此我们需要制定版本号。在arch下,本人是直接使用yay(需要自行安装)进行下载。
yay tcl85 // yay tk85
这样的命令行即可。然后我们进入sim文件夹下。使用make编译。发现报错了。出现了类似这样的错误信息。

我们需要更改makefile文件。如下图所示(记得对照清楚一下)。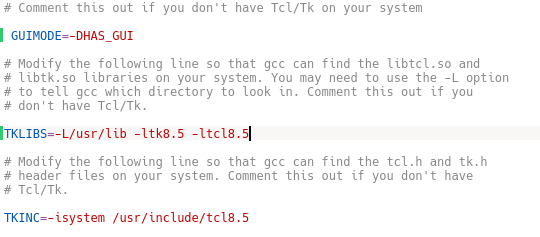
再次进行编译。又报出新的错误。错误信息大概是这样。
psim.c:23:10: fatal error: tk.h: No such file or directory
#include <tk.h>
compilation terminated.
看错误信息,我们发现,编译的时候找不到tk.h这个函数库。因此,我们去系统的函数库里面看一下,进入Root/usr/include文件夹下,ctrl+f搜索,我们发现tk.h放在了tk8.5这个文件夹下,因此编译的时候在include文件夹下找不到tk.h。我们只需要将psim.c中的tk.h更改为tk8.5/tk.h即可。(同理,ssim.c也需要修改)
好了,这个时候再次编译,我们又发现还是过不了。出现了类似这样的错误信息。
/usr/bin/ld: /tmp/cc44VPBY.o:(.data.rel+0x0): underfined reference to ‘matherr’
matherr没有定义??这是怎么回事。我们进入matherr所在文件(psim.c和ssim.c)看一下。找到了这样的两行代码:
extern int matherr();
int *tclDummyMathPtr = (int *) matherr;
直接注释掉即可。最后,我们再进行编译。在sim文件夹下make clean; make 我们成功地完成了GUI界面的编译。当然,要是过不了也没有什么关系,我们可以把上面图片中makefile那三行注释掉,这样编译出来的是文本界面,但不需要tcl/tk,也就不会一直报错了。
实验正文
part A
这部分其实没什么好讲的。就是简单地把一个函数翻译成y86-64代码而已。在misc文件夹下新建文件sum.ys,把自己翻译的代码打进去然后用yas编译,yis运行即可,最终%rax的数据为0xcba即正确了。自己可以进行校对。下面是我的sum.ys的代码。其余两个不贴上来了。主要是注意一下一开是要先设置pos,还有把栈顶放在%rsp上面即可。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36.pos 0
init: irmovq Stack, %rsp
call Main
halt
.align 8
ele1:
.quad 0x00a
.quad ele2
ele2:
.quad 0x0b0
.quad ele3
ele3:
.quad 0xc00
.quad 0
Main:
irmovq ele1,%rdi
call sum_list
ret
sum_list:
irmovq $0,%rax
jmp test
loop:
mrmovq 0(%rdi),%rcx
addq %rcx,%rax
mrmovq 8(%rdi),%rcx
rrmovq %rcx,%rdi
test:
andq %rdi,%rdi
jne loop
ret
.pos 0x100
Stack:
part B
这个部分同样比较简单,添加一个IIADDQ指令。文件位于/seq/seq-full.hcl 我们只需要在以下几个变量中添加IIADDQ的判断即可。
- instr_valid
- need_regids
- need_valC
- dstE中结果为rB的分支
- aluA中结果为valC的分支
- aluB中结果为valB的分支
- setCC
经过资料中的几个测试后,该题顺利解决。
part C
这道题很难,尤其是如果要追求满分的话。当然,要有分也没那么容易。在pipe文件夹下:
./correctness.pl // 检测自己的答案是否正确
./benchmark.pl // 测试自己的分数是多少
这道题我们能操作的文件就只有pipe.hcl和ncopy.ys。也就是说,分别从硬件和软件两个方面进行优化。首先是hcl文件,很显然,官方资料已经提示了我们,本题需要实现iaddq指令,这样做起来方便很多,可以将CPE降到13左右吧。虽然还是0分。具体和part B极其相似,这里不再赘述。
由于资料中还提示我们,建议去看loop unrolling的部分,这告诉了我们,本题最大的优化在循环展开这里。于是,笔者不得不先提前去看了一下书上循环优化部分的内容。为什么循环优化能够提高那么多呢?
注意到我们的每次循环过程中,迭代器都要+1,并且src和dst两个指针也要对应地发生移动,然而,这样的指令对于我们答案的得出并没有实质性的直接帮助,因此,我们应该尽量减少这样的指令的产生比如:1
2
3
4
5
6
7int sum = 0;
for (int i = 0;i < n; i++)
sum += a[i];
int sum = 0;
for (int i = 0;i < n; i+=2)
sum = sum + a[i] + a[i+1];
两个程序进行对比,很明显,下面的程序的效率要远远高于上面那个。尤其当n越大时,效果更明显。而题目给的程序中,需要递增的有三个数,这就使得循环优化变得更加重要。对于循环k路的选择上面,个人选择了k = 8。即每次n的变化应该是8。总体上来说,和四路的效率比较接近。具体实现过程中,整体思路是,先将n - k, 然后再进行n/k轮迭代,最后再把余数进行处理。具体可以见最下方的参考
进行了循环优化以后,我们还发现,程序中有类似这样的两行。
mrmovq (%rdi),%r10
rmmovq %r10,(%rsi)
记性比较好的读者应该会记得,书中有提到过这样的例子。第二行的rmmovq指令执行到decode stage时,上面那一行还在execute stage,这个时候,我们并不知道(%rdi)的值具体是多少,也就是说,这个时候我们没办法通过data forwarding将数据送往decode stage。于是,rmmovq指令只好停留在本阶段,于是我们浪费了一个clock cycle,这是一种典型的load interlock, 处理办法是将另一个指令插入这两个指令中。然而下面的andq %r10,%r10指令我们也用不了,同样需要读取%r10,无法避免cycle的浪费. 因此,我们选择将下面的一个mrmovq提到上面来,即变成
mrmovq (%rdi),%10
mrmovq 8(%rdi),%r9
rmmovq %r10,(%rsi)
这样以来就不会发生cycle的浪费了。这个时候我们再进行测试的话,分数应该已经挺高了。当然,还有一些小小的优化可以调整。比如余数的处理上等等。这里给一个看到的处理得比较好的文章供参考,这篇文章作者还使用了一个三叉搜索树构造跳转表,再一次提高了效率(已经接近满分了)。这里我就不再赘述了。
其实我们会看到,想要提高CPE(CPI),其实最主要就是三个方面,一个是use/load的冲突,如上面的mrmovq和rmmovq,这会消耗掉一个cycle;第二个是return语句,由于pipeline的设计,我们不知到会跳哪个位置,只能等到return执行到memory stage的时候才能确定,这将会浪费掉三个cycle;还有一个就是JXX中的条件跳转(非条件没有影响),一旦分支预测错误,将会浪费掉两个cycle,而跳转指令在我们的程序中又特别的常见,因此,这是我们很大的一个优化方向,不仅是在这个实验当中。对于一个跳转指令,在特定的ISA下,我们应该尽量想办法在软件层面做处理,提高分支预测的准确率(比如在可能的情况下用data flow替换掉control flow)。书中也提到,现代的处理器的stage是远不止五个的,一旦分支预测出现错误,处理器调整的开销将长达十几个时钟周期。这个应该也是我看第四章留下的印象最深刻的地方吧。
下面是我的代码(其中也用到了其他一些小优化,比如分支的调整之类的):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138xorq %rax,%rax
iaddq $-8,%rdx
jl Test
Loop:
mrmovq (%rdi),%r10
mrmovq 8(%rdi),%r9
andq %r10,%r10
rmmovq %r10,(%rsi)
jle Npos1
iaddq $1,%rax
Npos1:
andq %r9,%r9
rmmovq %r9,8(%rsi)
jle Npos2
iaddq $1,%rax
Npos2:
mrmovq 16(%rdi),%r10
mrmovq 24(%rdi),%r9
andq %r10,%r10
rmmovq %r10,16(%rsi)
jle Npos3
iaddq $1,%rax
Npos3:
andq %r9,%r9
rmmovq %r9,24(%rsi)
jle Npos4
iaddq $1,%rax
Npos4:
mrmovq 32(%rdi),%r10
mrmovq 40(%rdi),%r9
andq %r10,%r10
rmmovq %r10,32(%rsi)
jle Npos5
iaddq $1,%rax
Npos5:
andq %r9,%r9
rmmovq %r9,40(%rsi)
jle Npos6
iaddq $1,%rax
Npos6:
mrmovq 48(%rdi),%r10
mrmovq 56(%rdi),%r9
andq %r10,%r10
rmmovq %r10,48(%rsi)
jle Npos7
iaddq $1,%rax
Npos7:
andq %r9,%r9
rmmovq %r9,56(%rsi)
jle Npos8
iaddq $1,%rax
Npos8:
iaddq $64, %rdi
iaddq $64, %rsi
iaddq $-8, %rdx
jge Loop
Test:
iaddq $8,%rdx
jne Rem1
ret
Rem1:
mrmovq (%rdi), %r10
mrmovq 8(%rdi), %r9
andq %r10, %r10
jle Pos1
iaddq $1, %rax
Pos1:
rmmovq %r10, (%rsi)
iaddq $-1, %rdx
jne Rem2
ret
Rem2:
andq %r9, %r9
jle Pos2
iaddq $1, %rax
Pos2:
rmmovq %r9, 8(%rsi)
iaddq $-1, %rdx
jne Rem3
ret
Rem3:
mrmovq 16(%rdi), %r10
mrmovq 24(%rdi), %r9
andq %r10, %r10
jle Pos3
iaddq $1, %rax
Pos3:
rmmovq %r10, 16(%rsi)
iaddq $-1, %rdx
jne Rem4
ret
Rem4:
andq %r9, %r9
jle Pos4
iaddq $1, %rax
Pos4:
rmmovq %r9, 24(%rsi)
iaddq $-1, %rdx
jne Rem5
ret
Rem5:
mrmovq 32(%rdi), %r10
mrmovq 40(%rdi), %r9
mrmovq 48(%rdi), %r8
andq %r10, %r10
jle Pos5
iaddq $1, %rax
Pos5:
rmmovq %r10, 32(%rsi)
iaddq $-1, %rdx
jne Rem6
ret
Rem6:
andq %r9, %r9
jle Pos6
iaddq $1, %rax
Pos6:
rmmovq %r9, 40(%rsi)
iaddq $-1, %rdx
jne Rem7
ret
Rem7:
andq %r8, %r8
jle Pos7
iaddq $1, %rax
Pos7:
rmmovq %r8, 48(%rsi)
总结
这个实验本身来说难度并不能算大,甚至比课后练习还要稍微容易一点,但是需要对CPU的pipeline有比较清晰的了解,否则做起来会特别的吃力。由于我自己本身是读软件方面的,对硬件很多东西其实也不怎么了解(基本上师兄在说的时候也是觉得这一章可以不用怎么看),加上现在才大一,很多知识,比如电路方面的都还没学,看得时候都要查一下一些概念什么的。当然最后我还是坚持顽强地把它啃下来了(算上实验和各种其他杂七杂八的东西,总共花了一个星期多一点吧)。花了很长的时间,尤其是pipeline那一块,到现在都觉得自己的理解并不是很到位,还有一些小细节没有搞清楚。我也不知到为什么一个读软件的要对涉及到已经几乎是硬件层面的东西要这么花时间,我也不知到自己花了这么长的时间去看这个究竟有没有意义。可能这就是对计算机的热爱吧(逃