Prologue
这篇文章主要介绍 mit6.828 实验 的完成过程(不包含所有实验)以及在 6.828 中学到的一些知识点。以实验的完成为主线,中间穿插一些知识点,目的是为了更好地理解这个课程中的一些知识和理念。下面开始吧。
(前面第一个实验做的是 2018 的,后面才改为 2019 的)
这里先附上我的仓库, 所有实验均完成. 每个任务对应在不同的分支当中. 查看每个分支增加的内容的话可以看每个分支和 xv6-riscv-fall19 分支的区别.
Lab Booting a PC
既然要讲到操作系统,那么不可避免的要涉及电脑的启动的知识。显然完整的启动过程是及其复杂的,涉及到了大量的硬件和软件的知识,这里只能简单地了解到启动过程中的一些关键步骤。以 x86 CPU 在 BIOS 引导下的启动为例。
取 CPU 正式通电作为启动的开始,这个时候,CPU 将会 RESET 到一个初始状态,CP:IP 指向内存地址为 0xFFFF0 的位置,此时 CPU 运行于实模式下,能访问到的内存空间的大小仅 1M. 通常情况下,在该内存地址处存在一条跳转指令,指向 BIOS 的代码。
BIOS 在进行一些初始化操作后,寻找硬盘中的主引导记录,并将引导启动的代码复制到内存区域 0x7c00 到 0x7dff 当中(共 512 Byte,刚好一个扇区)。然后使用跳转指令跳转到启动的启动代码处,此时 BIOS 就相当与将系统的控制权转交给了操作系统的引导代码。
Boot Loader
在引导代码中,首先将 CPU 的中断关掉,然后设置各个数据段的值,读取段描述符,然后将 CR0 寄存器置为 1,即启动保护模式。此后 CPU 的寻址方式也发生了改变。
1 | cli # Disable interrupts |
切换到保护模式下后,CPU 要做的首先是各种段寄存器的设置,保证各个段对应的位置是正确的。此后跳转到 bootmain 函数,在这个函数中,操作系统的代码将从硬盘移动到内存当中。
1 | void |
值得注意的一点是,由于此时还不存在操作系统,从硬盘读取文件仅能通过汇编代码实现(in 和 out 指令),此处代码对硬盘中文件的读取做了一点简单的封装(readseg函数)。
JOS 操作系统本质上就是个 ELF 文件,存放在硬盘中的固定位置处,因此,我们将读取 ELF 文件头,就可以获得数据段和代码段等的位置和大小,并将其移动到内存中的固定位置,这样就实现了从磁盘到内存的搬运。此后,只需要从 ELF 文件中获取操作系统入口的地址,并调用入口的函数,就实现了将控制权转移到操作系统的步骤,操作系统开始准备启动。
The kernel
上面最后进入的 e->e_entry 对应的地址就是 entry.S 代码的开始。此处的代码是这样子的:
1 | # Load the physical address of entry_pgdir into cr3. entry_pgdir |
可以看到,首先开启了分页模式,也是从这里开始,内存的 [KERNBASE, KERNBASE+4MB) 映射到了 [0, 4MB)。然后,由于 IP 还停留在低地址处,在此处设置一个跳转使其跳到高地址。然后就是栈指针的设置。此处,通过查看汇编代码(使用 readelf 或 objdump 都可以),可以知道,栈所在的位置是 0xf0108000 ~ 0xf0110000(不一定相同)。至于为什么此处 bootstacktop 的值是 0xf011000,可以通过 objdump -h 查看 kernel文件,恰好 data 段的开始就是 0xf0108000,加上段的大小是 32KB,因此栈顶就变成了 0xf0110000 了。然后,就跳转到了 i386_init 方法。
初始化代码是这样子的:
1 | void |
首先是进行一个 bss 段的清空操作。(bss 段在实际的 ELF 文件中仅仅存在段表,并没有实际占用任何磁盘空间)。然后,调用 cons_init 方法,在其中进行的是 cga 和 I/O 的一些初始化,具体细节可以不用管。到这里所有的初始化工作都完成了,程序可以正常运行。最后是一个死循环,不断调用 monitor 方法。在该方法中,循环读取用户的输入,并尝试执行用户输入的命令,即相当于一个简单的控制台。到这里整个程序的启动就基本结束。
mon_backtrace 实现
在实验中,要求我们实现一个简单的打印栈轨迹的方法。基本思路是利用汇编代码中,函数调用入口和出口出的典型形式(注意栈是往地址更小的方向伸展的,在下图表示法中则是向下):
1 | push ebp # 旧栈基址入栈 |
通过这样的特征,我们可以得到类似上面那样的栈结构,借助每个 ebp 存放的恰好是旧的 ebp 在栈中的位置这样的关系,形成了一个链表,我们可以打印出每个函数调用时的栈信息。边界是前面在刚刚进入保护模式的时候,ebp 的值为 0。以下是我的答案:
1 | int |
Lab Shell
shell 可以说是 linux 中和系统交互的窗口, 它读取我们输入的指令, 并进行解析和执行. shell 有很多个版本, 从比较古老的 sh, 到 csh, bash, zsh 等, 每个类型的 shell 都有其特色. 在这个实验中, 需要实现的就是一个简易的 shell. shell 的一般逻辑如下:
1 | char buf[MAXBUF]; |
在这个实验中考察的主要是重定向和管道. 首先, linux 中, 一般初始进程有三个文件描述符: 0, 1, 2. 0 代表标准输入, 1 代表标准输出, 2 代表标准错误. 在编程中, 通常 scanf 就是从描述符 0 中读入的. 而重定向就是用来修改输入和输出的目的地的. 比如
1 | cat file.c > a.out |
‘>’ 是输出重定向, 可以把执行 ‘cat file.c’ 的 1 号描述符从指向控制台变为指向 a.out 的文件. 结果就是 file.c 中的内容将会被输入到 a.out 文件中. 管道则是 linux 中的一种通信机制, 想象现实中的一条水管, 如果把数据看成是流动的水, 通过管道读写数据就像水流经水管一样. 并且, 水管是单向的, 一条水管中的只能从一边流向另一边, 管道也是如此. linux 中的 pipe 函数可以创建一个管道, 得到输入和输出的描述符. 利用这两个描述符, 就可以从管道中接受数据或发送数据. 不过一旦输入数据, 输出描述符将自动关闭, 反过来也是, 防止双向流动.
在实验中, 关于重定向有个很巧妙的写法:
1 | void |
pipe 创建管道后, 当想更换输入描述符时, 调用 redirect(0, fd), 同理, 更换输出描述符时, 调用 redirect(1, fd). 下图就比较形象地展示了这个函数的功能
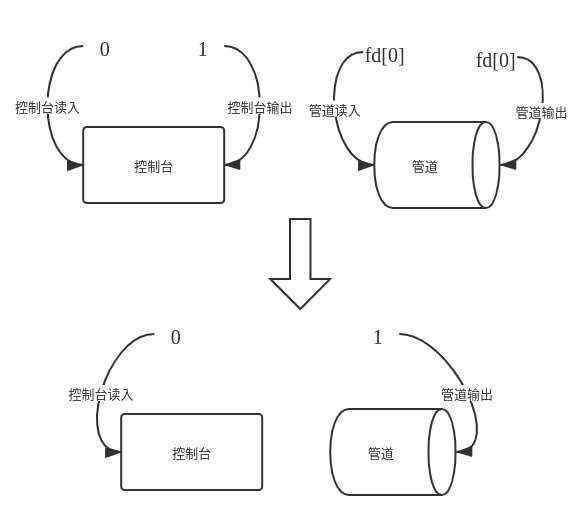
利用这个函数, 我们可以很简单地实现 ‘>’ 和 ‘<’. 而遇到 ‘|’ 符号, 则可以将前后的指令分为两部分 s1 和 s2, fork 后子进程调用 redirect(1,fd) 操作, 然后执行 s1 部分的指令; 父进程则 redirect(0, fd) 后执行 s2 部分的指令(有可能递归) 即可. 伪代码如下(仅思路, 具体代码不建议这样写):
1 | char* cmd = ...; |
写完后, make qemu 后, 调用 testsh nsh, 看到 passed all tests 则说明成功了.
Lab Mmap
mmap 实验应该是所有实验里面代码量相对较大的一个, debug 起来也比较麻烦. 建议在这个实验中写好打印 mmap 用到的相关数据的函数, 便于后面的调试. 在该实验中, 需要实现 linux 中的 mmap 函数的简易版本, 用于将某个文件映射到内存空间上. 在该实验中, addr 和 offset 恒为 0. flags 只分为 SHARED 和 PRIVATE 两种, 对于 SHARED 类型的映射, 在 unmap 后需要写回原文件, 而 PRIVATE 则不需要写回.
1 | void *mmap(void *addr, size_t length, int prot, int flags, |
和其他系统调用一样, 首先要做的是在 syscall.c 和 syscall.h 中添加 mmap 和 munmap 的系统调用号, 以及 usys.pl 中添加 entry. 这里我选择的是新建一个 mmap.c 文件, 在其中实现 mmap 相关的函数. 由于 mmap 是属于进程的, 为了便于对 mmap 映射区域的管理, 我添加了一个 vma 的结构体如下(写在了 proc.h 中). 结构体中包含每个映射区域的起始地址, 长度, flags, 映射的文件指针, 以链表的形式串联在一起.
1 | struct vma { |
在 mmap.c 文件中, 首先需要对 vma 结构体进行管理. 这里选择用一个固定长度的空的 vma 数组用于分配, 添加 allocvma 和 freevma 进行分配和回收, 使用链表的形式将所有未用的 vma 串联在一起. 在 mmap 中按照以下的思路进行:
- 检查参数的范围(比如 len > 0)
- 检查权限问题. 比如一个不可读的文件不可能使用内存映射给用户访问, 应该返回异常. 或者一个不可写的文件, prot 标志区域可写并且 flags 标记为 MAP_SHARED(即会写回源文件) 也是有问题的.
- 调用 allocvma 获得一个空的 vma 结构体
- 搜索当前进程的页表, 找到一个空闲区域, 并将区域的首地址, 长度等信息填写进 vma 中, 并加入进程的 vma 链表
- filedup 增加文件的引用数, 防止文件被提前回收
munmap 的思路同样类似
- 检查参数范围
- 从当前进程中查找到需要 unmap 的地址所在的 vma
- 如果有 MAP_SHARED 标识, 则写回. PTE_D(1<<7) 标志位表示页面被修改过
- uvmunmap 将页面回收
- 如果 vma 对应的空间全部回收, 则关闭文件, 并将该 vma 从进程中除去
这里有几个需要注意的点. 第一个是上面提到的权限问题的检查. 第二个是虚拟内存中空闲区域的查找, 需要注意空闲区域必须在当前页表中为空, 并且不能和其他空闲区域重叠, 否则会出现严重的问题. 此外, 由于使用了 lazy allocation, 要如何保证查找到的空闲区域不会被其他操作用到(虽然我没有进行额外的处理, 但可以通过测试). 第三个是 uvmunmap 需要进行对应的修改. 因为 lazy allocation, uvmunmap 的区域有可能实际上并没有分配到任何的物理内存, 这时候不应该 panic, 而是直接跳过.
在碰到缺页异常的时候, 需要先检查访问的地址是否位于 vma 当中, 如果是的话则需要分配一个新的物理页给进程, 并调用 mappages 进行地址的映射. 如果不在 vma 当中才触发 panic
最后 exit 和 fork 函数需要做适当的修改. 由于子进程继承了父进程的所有虚拟内存空间, mmap 的区域同样需要继承. 在 fork 结束前添加 vma 的复制函数, 将 vma 复制到新的进程当中即可.
1 | struct vma* r = p->vmhead; |
同样的, exit 函数将所有 vma 依次释放. 但需要小心一个链表操作的问题, 比如下面的代码可能出现严重错误.
1 | struct vma* r = p->vmhead; // 进程的 vma 链表表头 |
表面看起来似乎没问题, 但是在 munmap 函数中, 由于将整个 vma 回收, 会修改到 vma 链表, 并且 r 将会被回收, r = r -> next 是有问题的, 应该修改为 r = p -> vmhead
Lab FileSystem
这里根据 6.828 官网中的 book-riscv-rev0.pdf 相关介绍, 讲下简单文件系统的实现.
6.828 中的文件系统和早期 Unix 系统比较类似, 整个文件系统大致分为七个层次, 下面按照层次模型进行分析, 给出每一层的作用以及和上下层的交互关系.(这里的分层并不是很严格, 跨层之间的调用是存在的)

最底层是硬件层/汇编层, 直接和硬件进行接触. 对于上层而言, 它的作用是, 给定一个设备, 缓冲区以及需要读写的块号, 对硬件中对应的数据块进行读写. 对应于源文件中的 virtio_disk.c 文件. 通常这样一个层次包含了磁盘驱动程序以及对应的硬件.
上面一层是 Buffer 层, 顾名思义, 最直接的作用就是做缓存, 对于上层到来的所有读写请求进行缓存操作, 如果缓存中没有找到, 才向下一层也就是硬件层发出对应请求. 对应与源文件中的 bio.c 文件. 简单起见, xv6 采用的是 LRU(Least Recently Used) 的缓存策略. 这里是 buf 的定义:
1 | struct { |
可以看到, 整个缓存层其实比较简单, 包含了几十个预先分配好的缓存块, 一个缓存头, 以及一个自旋锁. 每个缓存块则包含较多的缓存相关信息, 包括 valid(当前块是否合法), dev(块对应的设备号), blockno(块对应于磁盘中的块号), refcnt(引用数), data(对应的数据) 等. 值得注意的一点是, 这里的 “块” 和磁盘的 “块” 指的不是同一个概念. 磁盘的读写单位为扇区(一般为 512 字节)或簇, 而这里的块指的是一个 buf, 为 1024 字节, 下文中的块均是指 buf. 接收到读缓存块的命令时, 先在 bcache.buf 中查找是否存在对应的块, 如果存在则直接返回, 没有存在则从向磁盘驱动程序拿, 再返回. 接收到写缓存块的命令时, 则直接调用驱动程序进行写入.
注意到缓存区存在锁, 并且每个缓存块也有对应的锁, 因此 Cache 层还有一个重要的作用就是同步所有对硬盘的操作, 这使得文件系统能够较好地支持多线程/进程.
再上来一层则是 logging 层. 首先考虑一个问题, 对于文件系统来说, 由于磁盘的读写速度是较慢的, 一个对磁盘的读写指令完全有可能会因为某些异常而被打断, 比如 crash. 这样一种现象有可能会造成严重的后果. 比如回收一个文件时, 如果出现 crash, 有可能导致文件系统持有对一个已回收区域的引用, 或者文件系统中存在一个没有引用但却占用空间的区域. 前者浪费了磁盘的存储空间, 后者可能会导致安全性问题(其他用户如果恰好分配到了这块区域则可以读取到数据). 因此, crash recovery 是很有必要的, 这就是 logging 层的作用. 对应于源文件中的 log.c
logging 的实现原理和 log 其实很相似, 对于每一个写入(transaction)操作(读取操作不需要考虑 crash 造成的问题), log 将需要写入的块的块号记录下来, 然后就返回, 并增加对应 buf 的引用(防止在 cache 层被回收). 真正的写入在 commit 过程中. 在每个文件系统调用结束的时候, log 层判断当前是否已经没有文件系统调用在执行, 如果有的话则执行 commit 操作. write_log 将当前在 log 中留有记录的块写入磁盘中的 log 区, 然后将 logheader(包含 log 的数量等数据) 写入 log 区. 然后再真正开始写入, 将 log 中的块写入真正的目的地, 最后再调用 write_head, 更新 logheader 并写入. 可以代入确定, 无论 crash 在哪一步前后发生, 都不会破坏文件系统结构.
1 | static void |
Crash Recovery 的操作是发生在文件系统启动的时候, 检查 log 区域中的 logheader 是否包含有已经 commit 但是还没写入对应区域的块, 有的块则将其写入到目的地. 另外, 除了保证文件系统的安全外, log 层还控制了每次文件系统能写入的最大数据(不能超过 log 区的大小).
再上来一层是 inode 层次, 这一层主要用来维护每个文件的信息. inode 总共分为两类, 一个是在磁盘的 dinode, 另一个是在内存中的 inode. 磁盘中的 inode 和每一个文件相对应, 包含文件的大小, 文件数据所在的位置, 文件类型, 对应的设备号等. 结构大概如下:
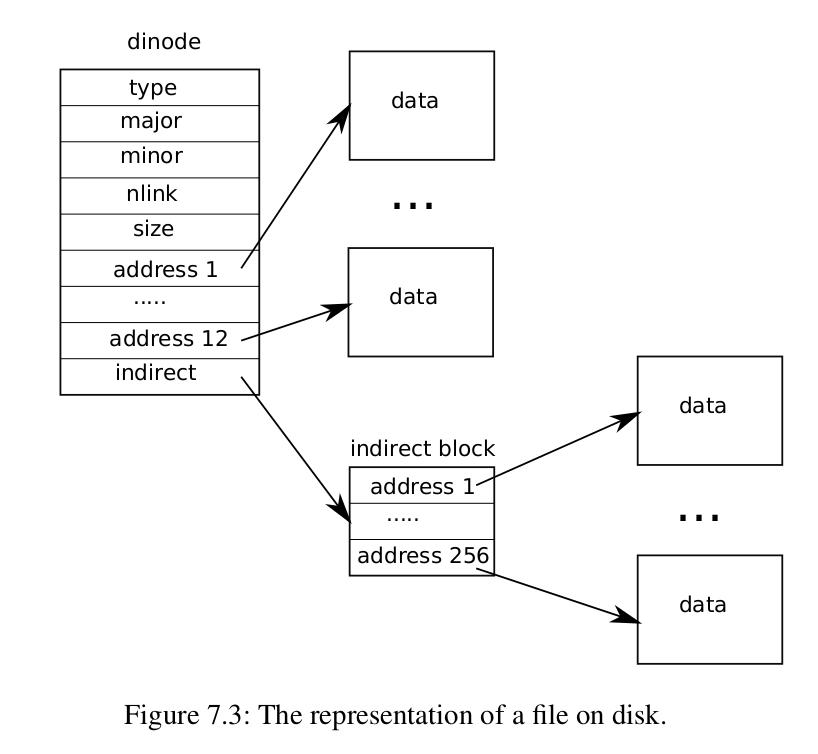
每个 dinode 中存放了 13 个地址(准确来说应该是块号), 其中前十二个指向了 12 个存储于磁盘的块, 第 13 个指向了磁盘中的一个 “目录块”, 这个块中每一个位置都指向了另外一个位于磁盘中的块. 每个块号占 4 字节, 一个块为一个 1024B, 因此一个文件能包含的最大的数据量为 (12+(1024/4)) x 256 = 68608 字节.
位于内存中的 inode 除了包含 dinode 对应的信息外, 还包含了一个锁(防止对文件的并发访问), 一个 inode number 等数据, 从这里开始到上面的层次中都是使用 inode 这样一个抽象来执行文件操作的. 相关的操作位于 file.c 和 fs.c 中. 到这里其实文件系统核心部分已经结束, 下面以对一个文件的 read 和 write 为例, 从上到下过一遍文件系统:
首先, 系统调用触发后, 根据调用号操作系统找到对应的实现函数的地址并跳转, 读入参数后, 系统调用 fileread 函数, 判断文件类型属于 inode(也有可能是管道或者设备等), 并为 inode 上锁后, 调用 readi 函数. 在 readi 函数中, 使用 bread 函数从 buffer 中读取 buf 块, 并将其内容复制到用户制定的缓冲区中.
而对于写数据则稍微麻烦一点. 和前面类似, 进入到 filewrite 函数, 这里需要处理一次写入的数据大小, 每次操作的数据块不能大于 MAXOPBLOCKS, 过大时需要分批调用, 等前面的数据执行完 commit 操作后再次写入. 注意到这里需要用到 logging 层, 因此, 锁定 inode 前还要调用 begin_op 和 end_op 操作, 确保 logging 层的正确运行. 然后调用 writei 函数, 和 readi 类似, 读取 buf 块后, 将数据从用户制定的缓冲区中复制到 buf 里面, 然后调用 log_write 函数将该写入操作记录下来. 退回到 filewrite 函数后, 执行 end_op 操作时, 如果此时不存在其他的文件系统调用的话则进行 commit 将所有 log 真正地写入磁盘当中.
Large file
实验的第一项任务是扩展文件的最大容量. 前面写到, 由于 inode 本身的设计, 一个文件最多只能包含 68608 个字节, 超过的话则无法处理. 在当前来看, 这样的容量显得过小了. 因此, 在这个任务中需要拓展文件的容量. 解决的思路整体上也比较简单直接, 更改 inode 的结构, 之前我们用的是一个一层的间接引用, 现在我们将再增加一个二层的引用. 13 个块中, 前面 11 个是直接指向数据块, 第十二个和之前一样指向一个 “一级目录”, 第十三个指向的具有 “二级目录”, 最后文件的最大的大小就可以变为 (11+256+256x256)x256 = 16845568 Bytes.
首先需要更改 inode 和 dinode 的定义, param.h 中 FISIZE 大小等. 需要修改的核心函数有两个, 一个是 bmap, 用于获取 inode 中第 i 个块对应的块号. 思路和前面其实类似, 目录为空则分配一个, 然后从 cache 中读取, 注意如果修改了 buf, 则需要调用 log_write 将改动保存.
1 | // 在 panic 前插入这几行 |
另外一个需要修改的则是 itrunc, 做法类似, 这里就不在赘述了. 使用 balloc 分配新的块, 使用 bread 和 brelse 进行块的读取和释放, 使用 log_write 保存更改.
Symbolic link
另一个任务是添加链接功能, 类似与 windows 中的快捷方式. 思路同样也比较简单. 在 stat.h 中添加新的文件类型的宏 T_SYMLINK, 然后添加新的系统调用 sym_link 以及 symlinktest 加入编译. 这种链接的思想是, 将想要指向的文件路径存放在当前文件当中. 打开这个文件的时候, 特殊判断如果文件属于 T_SYMLINK 类型, 则打开文件中存放的文件路径对应的文件. 因此, 需要更改的为 open 函数. 我的处理方法是, 文件属于 T_SYMLINK 函数时, 则调用 recur_open 函数, 实现如下:
1 | static int open_count = 0; |
在文件中进行递归调用, 同时为了防止循环打开, 这里使用一个静态变量进行计数, 每次调用 recur_open 前需要清零. 另外, 在 fcntl.h 中添加新的宏 O_NOFOLLOW, 表明直接打开文件而不根据文件中存放的路径递归地打开.
Lab net
网络应该是 xv6 实验中比较难调试并且难度较大的板块. 在该任务中, 我们要实现一个简易的网卡驱动, 支持使用 socket 进行简单的 udp 通信. 这里需要先过一遍计网的相关知识, 做起来会比较简单.
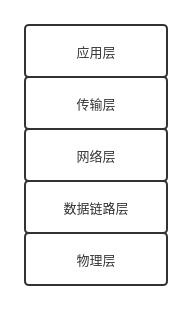
计算机网络现在广泛被人接受的应该是五层架构模型, 自顶向下分别为应用层(HTTP 协议等), 传输层(TCP, UDP 协议等), 网络层(IP 协议等), 数据链路层, 物理层. 每一层只和上下层之间具有直接的依赖关系. 对于大多数应用而言, 只需要用到应用层方面的信息. 在本实验中, 需要实现简单的 UDP 协议, 还需要接触到传输层.
Driver
第一个任务是写网卡驱动, 对应于 e1000.c 文件. 在这个任务中, 需要完成两个函数 e1000_transmit 和 e1000_recv. 动手之前需要先简单了解网卡驱动的实现原理. 这里是我的理解: 网卡是通过在网卡的寄存器上写入相应的值来进行控制的, 而每个网卡对于交互的要求(比如寄存器每个 bit 的含义)不一定相同, 因此需要有不同的驱动程序来实现. 据说, linux 的源代码中约有一半的源代码都是各种各样的驱动程序, 这应该也是原因之一. 操作系统使用内存映射技术将网卡寄存器的地址映射到虚拟内存空间当中, 我们只需要往寄存器中填入相应的值即可.
整个任务按照实验文档中给的提示就可以通过了, 事实上提示已经把所有需要做的事情写在了上面. 唯一需要注意一点的可能是 cmd 的设置. 完成后, 可以使用 make ping 进行测试.
1 | int |
Socket
第二个任务是实现 UDP 通信. socket 本身可以看做是一种文件, 这里使用 FD_SOCK 这样一种类型来标记 Socket. 在 file.c 中的 fileclose, fileread, filewrite 函数中需要添加对应的判断, 调用 socket 的关闭, 读写方法(在 def.h 中添加定义, 在 sysnet.c 文件中实现). 这里复习一下 UDP 协议.
UDP 协议是一种无连接的传输协议(与此相对的就是 TCP 协议). 本身 UDP 协议较为简单, 它只是在应用层报文上添加了一个 UDP 头, 其他几乎没有做任何处理. 不提供任何的拥塞控制, 顺序保证, 重传等功能. 这里是 UDP 头的结构:
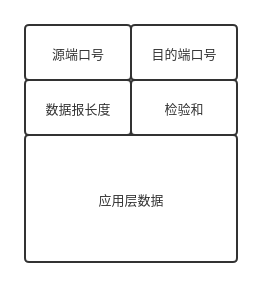
下面是简单的收发数据流程:
数据报到达网卡后, 触发中断, 进入 e1000_recv 方法, 网卡驱动程序将 buf 取出并上传到 net_rx, 再依次经过 net_rx_ip, net_rx_udp 方法去除每一层的报头, 最后到达了 sockrecvudp 方法. 在 sockrecvudp 方法中, 遍历 sockets 列表找到能处理当前 UDP 报文的 socket(注意使用锁), 然后添加到 socket 的 buf 队列当中, 并唤醒等待数据到来的线程(在 sockread 方法中阻塞).
sockread 方法中, 由于 socket 可能为空, 需要先阻塞, 等待数据到来后再用 copyout 将数据复制到用户指定的缓冲区中, 注意 buf 读完的话要回收.
write 方法中, 则直接将数据复制到新建的 buf 中(注意要在头部预留足够的空间给后面的协议), 然后调用 net_tx_udp, 依次经过 net_tx_ip, net_tx_eth, e1000_transmit 函数, 数据报发送到了网卡, 经由网卡将数据发送出去, 完成写入功能.
sockclose 方法思路则很简单, 从 sockets 列表中取出 socket, 并将该 socket 中全部的 buf 取出并回收, 然后再将 socket 回收即可. 代码的话在 github 中有, 这里就不贴了.
Epilogue
到这里整个 mit6.828 系列的实验就结束了. 可以看到, 整个实验难度基本还是落在后面的几个实验当中, 通过做这样的几个实验也加深了自己对操作系统这样一个复杂的概念的认识. 前前后后写实验以及完成小结花费了不少时间, 但现在看来还是比较值得的. 实际中的操作系统比本实验的明显要远远复杂的多, xv6 系统中存在的很多问题, 实际操作系统基本都能解决, 在很多地方应该也有着各式各样的优化. 也正是这些一个个问题的解决, 才有了我们今天能够流畅运行的计算机.