Prologue
这篇博客主要是想记录一下关于 opencv 这个库的一些学习心得,并穿插一些图像处理的基本知识。
分析基于 opencv 4.5.1,其他版本可能会存在一些接口的变动,还请注意。
Prep
首先是 opencv 的安装。对于 python 版的 opencv,可以直接使用 pip install 进行安装。对于 C++ 版则可以自己下载源码进行编译与安装。这里介绍在 ubuntu 下如何编译源码:
工具: git、cmake
首先需要下载源码:
git clone https://github.com/opencv/opencv
由于 git 可能较慢,linux 或 mac 下可以使用 wget/curl 等指令利用代理进行下载,以加快下载速度。
其次是配置,opencv 的配置需要用到 cmake。
mkdir build && cd build // 新建 build 文件夹用于构建
cmake .. // 生成 makefile 文件
make && make install // 编译并安装
注: 编译选项可以在 cmake 生成 Makefile 的时候进行配置。另外由于项目较大,编译耗时较长,也可以加上 -j4 等利用多线程进行编译。
调用 cmake 的时候如果报错提示需要创建另一个文件来存放编译产物这样的信息,可以试下把 CMakeCache.txt 删掉。
安装完毕后,可以使用简单的 demo 进行测试。
C++:
1 |
|
CMakefile:
1 | cmake_minimum_required(VERSION 2.8) |
最后使用 CMake 还有 make 进行编译即可。找一张图片测试下如果能正常展示出来应该就没问题了。
当然也可以使用 g++/clang++ 等直接进行编译,但需要注意链接的时候要加上 opencv 的二进制文件。
Arch
opencv 的项目文件结构的安排同样是按照模块进行划分的,源文件基本都放在了 modules 文件夹下。其中,几个重要的模块如下:
- core,包含一些基本的类定义,比如矩阵类 Mat,以及 mask,blend 操作等
- imgproc,包含大量图像处理算法,也是这个博客的重点
- highgui, imgcodecs, videoio,包含图像/视频的编解码等功能
- feature2d,包含 2d 图像特征检测相关的 api
- calib3d,3d 摄像机相关的库
对于每个模块,基本的文件结构如下:
- doc 包含模块相关文档
- include 包含模块的头文件(.hpp)
- misc 包含其他语言的一些源文件,包括 python,java,oc 等
- perf 包含性能测试相关文件
- src 模块源文件
- test 包含单元测试相关文件
Read / Write / Show
使用图像前往往对图像进行读取。api 如下:
1 | Mat imread( const String& filename, int flags = IMREAD_COLOR ); |
对应的实现在 imgcodecs 模块中的 loadsave.cpp 文件中。做一定的检查并初始化一个 Mat 容器,然后调用同一个文件中的 imread_ 函数。化简后的步骤如下:
1 | static bool |
经过这样一个步骤,图片就会根据具体的类型调用能解码对应类型的图像解码器,readData 将文件读取到矩阵当中。最后返回 true 表示读取成功。每种类型的图片的读取方式都不太相同,但最终都会转化一个矩阵的形式(通常为 BGR 或者灰度图),此后的处理就都是针对矩阵了。
写操作类似,首先是搜索找到一个合适的图像编码器,然后将类型传入,设置好目的文件名,然后具体的写入逻辑就转交给编码器了。
imshow 位于 highgui 模块的 window.cpp 中。定义如下图所示:
1 | void cv::imshow( const String& winname, InputArray _img ) |
绘图的逻辑中,总共有两条支线。如果可以使用 opengl,优先使用 opengl 进行绘制(目前默认没有使用 opengl)。如果不支持 opengl,opencv 还提供了 gtk,qt,w32,winrt 等绘图 api。cv 这个命名空间中的几个 cvUpdateWindow, setOpenGlDrawCallback 函数等为空实现。如果配置中选择了相应的库,则加入编译。这样就做到了动态地配置绘图实现方式。
Dip
图像处理涉及到的知识面十分复杂,因此这里仅选择 filter,canny,morphology 三个比较重要的部分,分析源码是如何实现的。
Filter
滤波是图像处理中的一个核心步骤,C++ 层接口如下:
1 | CV_EXPORTS_W void filter2D( InputArray src, OutputArray dst, int ddepth, |
opencv 中的 filter2D 并不是数学意义上的卷积,而是相关(Correlation)。数学上的卷积需要先对核进行翻转操作。如果核范围超过了图像,则使用给定的 border 模式对图像进行插值。经过数值提取后,函数的实现如下(位于 imgproc 模块的 filter.dispatch.cpp 文件中):
1 | bool res; |
可以看到,滤波函数的处理总共有三种分支。第一种是 replacementFilter2D,使用 ipp(Integrated Performance Primitives, 包含一套硬件实现的高速算法)。如果不支持 ipp,则采用第二种方式,即基于 dft(逆傅里叶变换) 的滤波方式。最后在没有其他可行的方式的情况下,才采用最原始的方式进行计算。
ocvFilter2D
ocvFilter2D 中,调用 createLinearFilter 函数创建一个 FilterEngine。
1 | static void ocvFilter2D(...) { |
createLinearFilter 中又调用了 getLinearFilter 函数获取线性滤波器,然后将其包装在 FilterEngine 内。getLinearFilter 最后又用到了 filter.simd.hpp 中 Filter2D 这个模板类。
apply 函数中调用到了 FilterEngine__apply 函数。先是使用 FilterEngine__start 进行初始化以及校验的工作,然后调用 FilterEngine__proceed,最后调用到的是 Filter2D 的 operator() 实现滤波的(本质上还是两个 for 循环实现的)。
dftFilter2D
使用 dft 版本的 滤波器如下: 首先会根据硬件是否支持以及原矩阵和目标矩阵的类型决定最大的核的大小。如果核很小,则返回 false,表示不采用 dft 方式,最后就会使用线性滤波实现。通常核大于 11 x 11 时就会采用 dft。
条件检查过后,会创建一个新的 temp 矩阵,然后调用 crossCorr 进行计算,最后再将 temp 矩阵拷贝到 dst,然后返回成功信息。
1 | static bool dftFilter2D(...) |
crossCorr 函数的实现在 imgproc module 的 templmatch.cpp 文件中。实现较复杂这里就不再贴上来,基本的思路就是: 计算出一个合适的 dft 后的矩阵大小,将原图像以及核都分别进行 dft 操作,然后在频域空间上进行相乘(调用了 mulSpectrums 函数),最后再使用 idft 还原到原来的大小。其中最复杂的点在于矩阵的大小的确定: 过小会导致精度的丢失,过大则增加了计算的复杂度。最合适的大小在 opencv 中是 hardcode 的:
1 | // 枚举 2^32 以内所有最佳大小,最后使用二分查找计算得到一个最合适的大小 |
Medium Filter
中值滤波在图像处理中也比较常见,实现位于 imgproc 模块的 mediun_blur.dispatch.cpp 文件中。
1 | void medianBlur( InputArray _src0, OutputArray _dst, int ksize ) |
进一步分析,进入 medianBlur.simd.hpp 文件中查看 opencv 内置的中值滤波的实现方式。
1 | void medianBlur(const Mat& src0, /*const*/ Mat& dst, int ksize) { |
可以看到,中值滤波一共有三个出口。首先根据核的大小(3 或者 5)判断是否使用 SortNet,是则进入 medianBlur_SortNet 方法。然后再次根据核大小判断,核比较小则采用一般的 Om 的一个中值滤波器,核比较大时,则使用一个 O1 的中值滤波器。
下面再进入 medianBlur_SortNet 方法查看实现。可以看到,这里只处理 m = 3 和 m = 5 情况下的中值滤波。同时,这个方法是一个泛型方法,传入的是 Op 和 VecOp 这两个类,分别对应于两个值之间的大小比较以及两个向量之间的大小比较。
1 | template<class Op, class VecOp> |
Op 的实现在同个文件中的 MinMax? 类,? 分别为 8u,16u, 16s, 32f。具体操作是在第一个参数比第一个参数大的时候交换这两个数。注意到 MinMax8u 对应的类中的 operator() 方法有点不同:
1 | int t = CV_FAST_CAST_8U(a - b); |
另外,如果没有启用 CV_SIMD(Simple instruction multiple data,硬件级别的优化),VecOp 则和 Op 是等价的。这个方法中一个比较大的优化是,使用了循环展开,并用多次 MinMax 操作将获取中值,而不是使用循环遍历,加快了代码的执行速度。
另外一个实现中值滤波的方法 medianBlur_8u_Om 的实现则完全不同。一个比较有趣的点是: 它计算中值的方式是直接统计核覆盖的矩阵中 0 ~ 255 的像素点出现次数。然后只要遍历查看某个 x 的出现次数大于核的大小的一半,结果矩阵中就把 x 填入。这样导致的问题是,最坏情况下每次要遍历 256 个值,因此算法中采用了一个简单的优化: 使用区间统计。用一个新的大小为 16 的数组表示分别表示 [0..15], [16..31]… 的出现次数。这样在寻找中值点的时候速度就要快了很多,最坏情况下只需要遍历 32 个值即可得到中值点。
Canny
Canny 算法是很经典的边缘提取算法,opencv 的 imgproc 模块有一个单独的 canny.cpp 文件负责完成 canny 算法。入口函数如下:
1 | /// src 为输入矩阵,dst 为输出矩阵 |
可以看到,核心的计算函数就是 parallelCanny,利用多线程进行计算,计算的流程可以拆分成下面几个步骤(不考虑 SIMD 的情况下,考虑 SIMD 的话部分代码会有些不同):
sobel 算子
canny 的第一步是使用 sobel 算子计算每个点在 x,y 方向上的梯度,核心的两个函数调用如下:
1 | if(needGradient) |
根据给定的参数,参与计算的 sobel 的核为:
kernelX = [[-1, 0, 1]]
kernelY = [[-1],[0],[1]]
计算的结果保存在 dx,dy 这两个矩阵中:
Edge detect
为了更好地利用空间,此处使用了循环 buffer 来保存图像中每一行中各个点的强度(magnitude)大小。mag_a 表示当前行,mag_p 表示上一行,mag_n 表示下一行。
1 | AutoBuffer<int> buffer(3 * (mapstep * cn)); |
接下来遍历线程所负责的每一行,计算 magnitude 的大小。然后再进行非极大值抑制,得到每个点是否属于 edge 的相关信息。用矩阵 pmap 表示,每个点 2 表示这个点是边,1 表示这个点不可能是边,0 表示这个点可能是边。
1 | /// rowStart 和 end 分别表示当前线程所负责的图像的行 |
Edge track
前面的函数中,已经计算得到了 pmap 表示每个结点是否可能为边这样的信息。双阈值要求算法需要对于可能为边的结点,仅当周围八个点中存在一定为边的结点才能计为边,否则当前点不属于边。因此,算法使用了栈这样的数据结构来实现,所有一定为边的结点入栈,处理每个结点时周围八个结点如果存在可能为边的结点,则标记为边并入栈,直到栈为空。
1 | while (!stack.empty()) |
上边步骤结束后,由于只在局部进行了 edge track 的操作,边界上可能还会有些问题,因此 opencv 的 canny 算法还增加了一个全局的 track 操作,代码和上方类似,不再赘述。
Final pass
最后的一个步骤就是把 pmap 中标记为 2 的点映射到 255,0 或 1 则映射到 0。代码如下:
1 | // the final pass, form the final image |
注意到代码中 pmap+1 是因为 pmap 在原图像基础上加上了一个宽度为 1 的边界。
uchar 则表示 uchar 类型的 0,pmap[j] >> 1 后仅当 pmap[j] = 2 时才为 1,因此最后就将 2 映射到了 255(白色), 0/1 映射到了 0(黑色),即得到了边界提取后的图像。
Morph
morph.dispatch.cpp 类中提供了一个构造形态学操作的核的一个方法,如下:
1 | Mat getStructuringElement(int shape, Size ksize, Point anchor) |
可以看到总共有三种形状的核,分别对应如下:
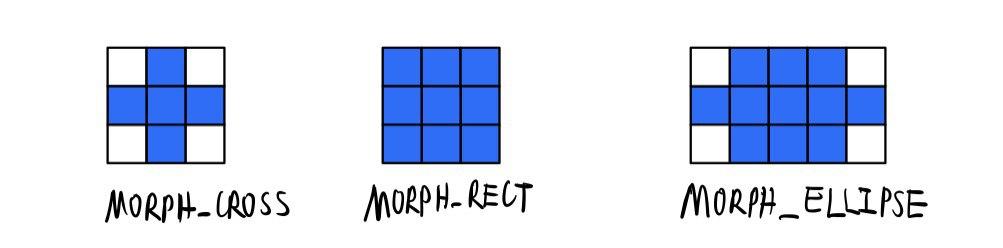
注意到上图是以中点为中心(Anchor) 的,也可以以其他点为中心的操作(相当于对图像做了偏移)。
另外,各种形态学相关操作最后基本都转化为 erode 和 dilate 操作。几种常见的形态学操作如下(位于 morph.dispatch.cpp 文件中的 morphologyEx 方法中):
1 | switch( op ) |
dilate 和 erode 两个操作统一用到了 morphOp 方法。接着调用到 morph 方法。这个方法中会提供一个空的 cv_hal_morph 方法供用户自行定义 morph 方法的实现。若没有自己定义的实现,则调用 opencv 内置提供的 ocvMorph 方法。和其他滤波器类似,在该方法中,调用了 createMorphologyFilter 得到一个 FilterEngine,最后调用 apply 方法进行计算。最后实际进行图形学滤波运算的是 MorphFilter 这样一个模板类:
1 | template<class Op, class VecOp> struct MorphFilter : BaseFilter |
对于 erode 和 dilate 两种操作,只需要分别传入 MinOp(返回值更小的那个) 和 MaxOp(返回值更大的那个) 即可。以 erode 为例,传入 MinOp 之后,对于核上每一个为 1 的点,覆盖到图像上的对应位置也必须为 1,否则由于 min 操作的特性,只要有一个是 0 最后的结果就会是 0,这个操作的结果就是,将核中心放在结果图像上任意一个为 1 的点,都能够被原图像包裹,即结果图像是源图像的腐蚀。膨胀则使用最大值,分析类似。
Python extension
opencv 的代码是由 C++ 编写的,但它同时也提供了 python 的库,这是怎么做到的呢?这就是 python 的扩展了。官方文档中提供了一个 Python.h 的库给开发者使用,里面提供了各种各样的用于 C++ 和 python 交互的 api,例如:
1 | PyModule_Create /// 创建一个 python module |
这样,对于每个需要暴露给 python 的 C++ 方法,只需要创建一个包装方法(包装类),最后将结果作为一个 python 对象返回即可,类似下面的代码:
1 | static PyObject * |
然后,需要再加入 PyInit_xxx 名字的类,进行 module 的创建工作。编译完成后,启动 python,调用 import 后 python 解释器会找到 PyInit_cv2 这样的名字的函数并调用这个方法,我们就只要在这个方法内部创建 module 以及添加模块内的方法即可。
opencv 中,init 函数位于 python module 下的 cv2.cpp 文件中:
1 | PyObject* PyInit_cv2() { |
init_body 函数中,依次创建每一个子模块并把函数签名传入。
包装类和包装方法则是由 python 模块下的 gen2.py 和 hdr_parser.py 生成的,在编译期间会自动运行这两个函数以生成转换代码。gen2.py 调用 hdr_parser.py 依次解析每个模块对应的头文件,根据 CV_EXPORTS_W,CV_WRAP 等宏标识某个函数/类是否需要生成中间转换代码。编译生成完毕后,运行期间就由 python 解释器自己查找对应的函数区执行了。
Epilogue
到这里 opencv 源码的学习就告一段落,在学习 opencv 的过程中遇到了不少问题: 各种 #define 套娃,函数参数多而杂,为了提供一个函数的多个实现而使用了大量条件编译,部分函数完全没有注释等。此外,网上几乎没有可用的中文参考资料也加大了阅读难度。当然看源码的过程中也学习到了大型项目的一些设计方法,包括但不限于充分利用模块化,在恰当的地方使用条件编译,typedef 等。