序
这是csapp系列的第七篇文章。具体题目请见官网。本文主要讲csapp中的malloc lab的一些问题以及解决办法。如果有什么写得不好的地方,欢迎联系我修改(右下角小图标点开即可对话,可能要稍微等一会)。
建议在开始实验以前,先把官方的资料看下。然后,本实验总体难度偏高,至少算是笔者目前花的时间最多的一个实验(算上各种调试,以及写博客花了大概三天吧),强烈建议把书里显式分配列表的地方看得十分清楚再开始写,不然一开始会无从下手。同样的,本实验需要对数据的存储(chapter 2),指针等内容有一定的了解,需要经常用到各种类型转换。
倘若你是在官网上下的文件的话,建议找一下完整的trace文件,官网中仅含有两个简单的测试文件,没办法进行较大的数据的测试。
mallco 的简单实现原理
内存空间的申请
在不使用malloc的情况下,通常我们需要使用系统调用来获得内存,其中最主要有两个方式。
第一个是sbrk(brk)函数:1
2
3
int brk(const void *addr);
void *sbrk(intptr_t incr);
brk的作用是将堆顶指针设置为addr,失败返回0,成功返回1。而sbrk的作用是将堆顶指针增加incr个字节,成功返回新的堆顶地址。
第二种方法使用的是mmap函数,利用匿名映射来实现。1
2
3
void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
int munmap(void *start, size_t length);
其中,start指针表示想要映射的内存区域的起始地址,length为映射的大小,prot是保护标志,flags是映射的类型(匿名映射使用MAP_ANONYMOUS参数),offset是偏移量。
munmap则是将映射的空间还给操作系统。
当然,mmap还有另一个重要的作用就是实现快速的I/O,它通过直接将文件映射到虚拟内存,可以直接对其进行读写操作,而不需要使用系统调用read/write,大幅度提高了速度。当然,它只适用于内容的更新,而不适用于内容的添加。同理,使用mmap还可以实现共享内存。
在实际的使用中,我们不可能每次需要内存的时候,都用sbrk或mmap函数(系统调用速度很慢),这会大幅度降低我们程序的效率。通常我们采用的是一种类似于缓存的思想,使用sbrk函数向内核索取一大片的内存空间,然后,我们再使用一定的手段对这段空间进行管理,当这段空间不够用时,再向内核拿,这样就提高了效率。这也正是malloc函数库所起到的作用。
malloc & free
简单来说,malloc函数主要是通过维护一个空闲列表来实现内存的管理的,具体涉及到的数据结构就是链表。对每一个内存块,我们使用链表将它们串在一起,当需要使用的时候,我们从链表中寻找大小适合的内存块,并且从空闲链表中删除,拿给用户。
当用户用完某个内存块的时候,我们就将其重新插入回空闲链表,这样就实现了简单的内存分配和释放。
但是,这样的实现很明显空间利用率太低了,如果我们当前有个10kb的块,而用户仅需要1kb,这个时候直接分配就过于浪费,因此我们需要对这个块进行切割,拿出1kb给用户,剩下9kb重新放回链表,这样就可以提高一定的利用率。
但我们又发现,如果一个很大的块一直被切割,最后剩下的都是一些零碎的内存块,这个时候我们如果需要一个很大的内存块,这就有问题了,因此,我们需要合并。将几个临近的空闲块合成一个大的块,这样在需要大块内存的时候才有办法。
malloc lab
这个实验,要求我们完成一个动态内存分配器,即模拟libc库中的malloc, free, realloc等函数的功能。本实验我们仅需在mm.c文件中修改,其他的文件我们不需要进行改动(原始的mdriver.c可能会报错,根据提示自行修改即可,或者也可以无视)。最后我们的成绩是用时间效率(每秒操作数)和空间效率(共用了多少空间)衡量。当然,在本实验中,最大的难点在于空间效率的利用上。
实验文件:
mm.c 我们需要填写的文件
mdriver.c 用于测试我们的程序
memlib.c 模拟内存系统,含有mem_sbrk等函数
需要填写的函数:
int mm_init(void)
void *mm_malloc(size_t size)
void mm_free(void *ptr);
void *mm_realloc(void *ptr, size_t size);
实验要求及一些注意事项
- 在本实验中,尽量将所有的结构(链表头等)放在堆内存当中,尽量少定义全局变量。
- 64位与32位的问题。我们运行的机器应该是64位的,但是在目前csapp官网的makefile文件中有 -m 32 的编译选项,也就是说所有的指针均为32位,即占用4个字节,这点要注意。在某些linux系统中,电脑中可能没有对应的32位的库,因此在编译的时候会显示找不到库,根据自身系统自行下载即可。
- 本实验要求实现8-bytes对齐,也就是说,mm_malloc返回的指针均为8的倍数。
- 建议在确定好block的组织方式后,完成mm_check()函数,用于检查堆内存是否出现问题。
- 建议将trace文件夹放在mdriver所在文件夹中,并且更改config.h文件当中TRACEDIR的宏定义为
#define TRACEDIR “traces/“。
make之后就可以直接运行./mdriver进行全部测试
也可以使用./mdriver -f命令对某个文件进行测试 - 对于一些奇怪的段错误,不妨采用打印堆内存的信息,或者模拟指令,或者自己造一个小文件进行测试等。
在正式开始实验以前,请确保理解以下概念(包括各自的特点,优缺点等):
1. 三种适配方式:
- fitst fit
- next fit
- best fit
2. 三种空闲列表的组织方式
- implicit free list
- explicit free list
- segregated free list
3. 两种合并的方式
- immediate coalescing
- deferred coalescing
4. 两种内存碎片
- internal fragmentation
- external fragmentation
5. 空间列表的排序方式
- size order
- address order
适配方式
first fit: 最为直接的办法。扫描所有的块,只要当前块的大小满足要求就使用,速度较快。但容易导致空闲列表中前面的块被不断地细分,而后面的一些块却一直迟迟得不到利用。
second fit: 扫描的时候,每次从上一次扫描的下一个块开始,这样可以使得整个列表的块都可以被使用,这使得效率更高。然而,实际应用中,作用也很有限,容易产生很大的空间浪费,造成大量碎片。
best fit:这种方式最大的好处是可以充分地利用空间。找到所有满足要求的块中最小的那一个,这样可以很大程度上避免浪费。当然,这也使得时间成本较高,尤其是如果空间链表的组织方式不太恰当的话,容易导致每次都要遍历一整个列表。
在本实验中,要拿到高分一般采用的是best fit。
列表的组织方式
implicit free list:这种方式最为简单,直接将所有的块(不管是否有分配)串在一起,然后遍历。这种方式可也使得块最小可以达到8 bytes。当然,这种方式效率很低,尤其是当块的数量较多的时候。
explicit free list:在每一个free 块中保存两个指针,将所有空闲的块组成一个双向链表。和隐式相比,这种方式最大的好处在于我们不需要遍历已经分配的块,速度上快了很多,当然,由于需要保存指针,所以每一个块最小为16 bytes。
segregated free list:这种方式的特点在于,根据块的不同大小,分成k组,组织成k条双向链表。分类的方式有很多,比如可以采用2的倍数的分类方式,{1},{2},{3~4},{5~8}……大小为6的块放在第四条链中,大小为3的块则放在第三条链中等等。在本实验中,笔者采用的分类是{1~16},{17~32},{33~64},{65~128},{129~256},{257,512},{513~1024},{1025~2048},{2049~4096},{4096~…};
两种内存碎片
internal fragmentation:内部碎片,即是已经被分配出去(能明确指出属于哪个进程)却不能被利用的内存空间。比如当前我需要44 bytes的内存,然后malloc的时候分配到了一个48 bytes的块,这样的话,剩下的4 bytes的内存尽管我不需要用到,但是其他程序也无法使用,这就是内部碎片。
external fragmentation:外部碎片,即还没有被分配出去(不属于任何进程),但由于太小了无法分配给申请内存空间的新进程的内存空闲区域。这个比较难理解,这里用一张图来说明一下。
假设上面是内存的一部分。这个时候我如果想要一个大小为3 bytes的内存,我们发现尽管这部分总共有4 bytes的内存没有被我们用到,但是它们被隔开了,我们无法利用。因此,在这种情况下,内存中的这两个没有用到的部分就是外部碎片。需要注意的是,外部碎片和我们请求的大小有关。比如这个时候我要的如果是2 bytes大小的内存,我们发现中间的块是足够的,因此这个时候这个就不算外部碎片了。
about pointer (review)
C语言的指针向来是一个难点,在这个实验中,我们需要对指针有一定的理解。本质上而言,指针和其他int,long等类型的数据的存储并没有什么区别,同样是一串数字,指针更多像是C语言为我们提供的地址的抽象,使得我们能够更好地利用地址。
对于一个特定的系统以及编译环境下,指针的大小一般是一样的,通常32位系统下为32位(4 bytes), 64位系统下为64位(8 bytes)。准确上说,指针指向的是所指对象的首个字节。如下图,在一个小端法的机器中,一个大小为0x10f的int型数据存放在地址为0x7b3c~0x7b3f(共4 bytes)的内存区域中。每个字节占用为一个存储单位,对应着一个特定的地址。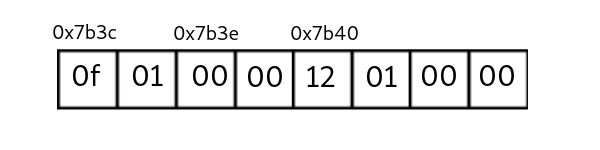
这个时候看下以下代码:1
2
3int n = 0x10f; // 假设n存放在上述的内存区域中
int* p = &n;
printf("%p %p", p, p + 1);
输出应该是多少?答案是输出应该为0x7b3c 0x7b40。对于一个指针而言,+1代表着增加一个单位长度,对于int型,大小为4个字节,故一个单位长度大小为4,倘若这个时候n的类型为short,则p+1的值应该为0x7b3e,依此类推。注意,一般情况下,指针之间的加法和乘除法是没有意义的。
继续看以下代码:1
2
3int n = 0x10f;
char* p = (char *)(&n);
printf("%d", *p);
这个时候的输出又是多少呢?答案是0xf。当我们使用取值符号时,得到的数字和指针的类型有关,同样是值为0x7b3c的指针,若类型为int,则应取四个字节,得到0x0000010f, 而如果是char类型的指针,得到的应该是0x0f,同理,若类型为long long,则得到的应该是0x000001120000010f。
因此,通过类型转换,我们可以实现很多意想不到的事情。
mm.c
allocated block 和 free block的具体结构如下。其中,successor存的是当前链表中下一个block的地址,predecessor存的是上一个block的地址。通过链表的形式将free block 串联在一起。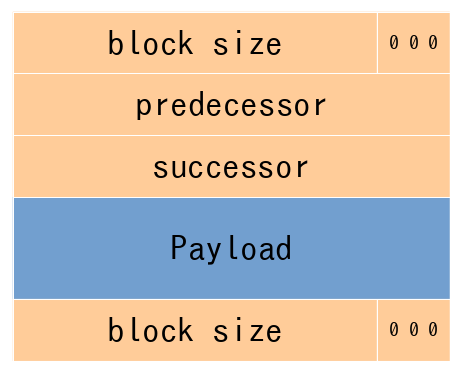
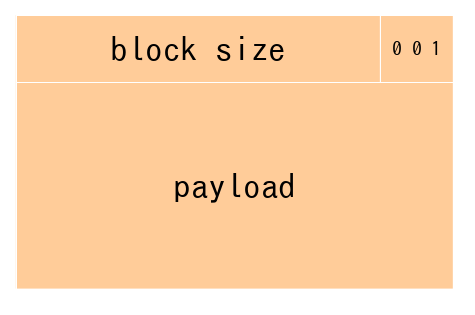
注意,这里有一个细节,allocated block中我们将脚部去掉了。与此同时,为了起到和脚部相似的作用,我们在flag位置中,用第二个位来标记上一个block(注意,这里的上一个是指在堆内存中的上一个块,而不是链表中的)是被占用。这样,只有当该标志位为0的时候,我们才认为上一个块是空闲的,可以用来合并。
define
对于这个实验来说,良好的宏定义有助于我们的理解。笔者的宏定义如下(仅列出部分):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22/* rounds up to the nearest multiple of ALIGNMENT */
全局变量
整个实验的全局变量如下:
static void* start_pos; // 永远指向当前堆的最顶部
static char* end_link_list; // 链表数组后的下一个块
static char* start_link_list; // 链表数组的表头
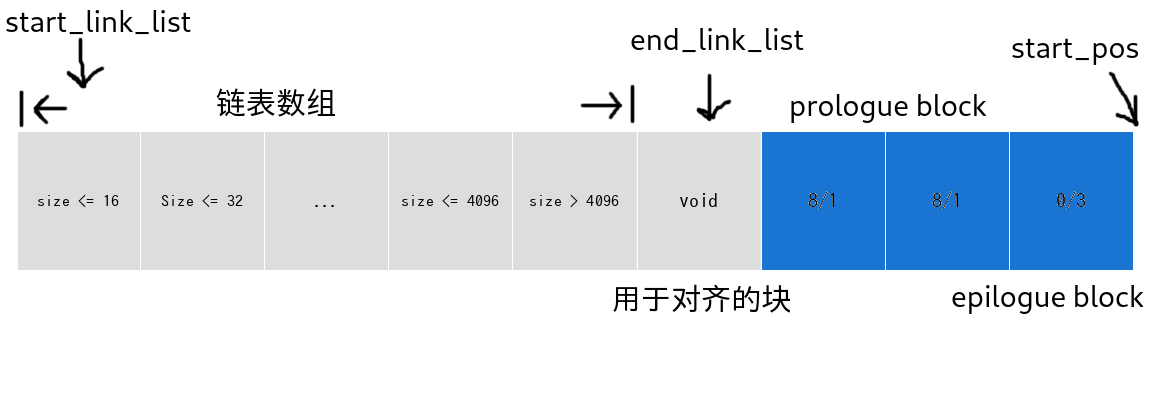
因为本次实验要求最好将数据存放在堆当中,因此我们选择将各个大小的链表头存放在堆一开始的一段连续区间中。具体存放如下(在mm_init函数中执行)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19if ((start = (char*) mem_sbrk(14 * WSIZE)) == (char*) -1)
return -1;
PUT(start, 0); // size <= 16, 因为最小的一个块大小为16,因此这里将size小于16的全部放在同一个链表当中
PUT(start + WSIZE, 0); // size <= 32
PUT(start + 2 * WSIZE, 0); // size <= 64
PUT(start + 3 * WSIZE, 0); // size <= 128
PUT(start + 4 * WSIZE, 0); // size <= 256
PUT(start + 5 * WSIZE, 0); // size <= 512
PUT(start + 6 * WSIZE, 0); // size <= 1024
PUT(start + 7 * WSIZE, 0); // size <= 2048
PUT(start + 8 * WSIZE, 0); // size <= 4096
PUT(start + 9 * WSIZE, 0); // size > 4096
PUT(start + 10 * WSIZE, 0); // for alignment
PUT(start + 11 * WSIZE, PACK(8,1)); // the prologue block
PUT(start + 12 * WSIZE, PACK(8,1));
PUT(start + 13 * WSIZE, PACK(0,3)); // the epilogue block
start_pos = start + 14 * WSIZE;
start_link_list = start;
end_link_list = start + 10 * WSIZE;
extend_heap
关于堆的拓展,我们需要注意到,每次拓展的大小都应该为8的倍数,这样才能保证8字节对齐。
其次,在拓展的时候,可以有一个小优化。假设我们需要拓展的大小为size。拓展时,我们先查看位于堆顶端的块,如果堆顶端是一个空闲的块,并且大小为msize的话,我们可以只拓展size - msize即可。这样的话可以在一定程度上提高空间利用率(针对某些比较特殊的数据效果很明显)。当然,这样的话也会使得整个程序效率降低(频繁使用mem_sbrk的话对程序性能的影响是很大的,这是一个系统调用)。
link_list
在本实验中,为了使用best fit,我们选择采用将链表按照从小到大的顺序排序,然后从头开始遍历链表,当遇到第一个满足要求大小的块,这个块就一定是最适合我们的。因此,我们每次插入某一个块的时候,别忘了要遍历链表,然后将该块放到正确的位置上,以维护链表的单调性。
find_fit
在寻找能放得下size个字节的最小的块的时候,我们有两种处理策略。笔者采用的方法如下:遍历当前的链表,寻找是否有满足要求的块,有的话就返回。另一种方法是只遍历size所在的链表,如果没有,直接返回NULL,交由后面堆去拓展。
第一种方法的话很明显时间上效率较低,但是能够保证较大的块能够被使用。后一种方法的话时间上效率较高,但是可能导致较大的某个块一直无法被利用,从而导致了空间的浪费。
1 | // getSizeClass 返回当前的size 值对应在第几条链表上 |
malloc & free
如下。有几个要注意的点。首先,分配内存的时候,我们需要一个大小至少为WSIZE(allocated block的头部) + size的块,且最小为16。如果小于16的话,会导致free的时候放不下,从而出现问题。其次,注意好标志位。free的时候下一个块的第二个标志位应该清零。以及free的时候,要顺便看下前后能不能合并,可以合并的话应该合并完后再插入到链表当中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24void *mm_malloc(size_t size)
{
size_t newsize = MAX(ALIGN(size + WSIZE), 16), incr;
void* addr;
// 这里我用findFitAndRemove寻找满足要求的块,找到的话顺便删除,没找到则返回NULL
if ((addr = findFitAndRemove(newsize)) == NULL) {
incr = MAX(CHUNKSIZE, newsize);
extend_heap(incr / DSIZE);
addr = findFitAndRemove(newsize);
}
return place(addr, newsize);
}
void mm_free(void *ptr)
{
size_t size = GET_SIZE(HDRP(ptr));
size_t prev_alloc = GET_PREV_ALLOC(HDRP(ptr));
AND(HDRP(NEXT_BLKP(ptr)), ~0x2); // 标志位清零
PUT(HDRP(ptr), PACK(size, prev_alloc));
PUT(FTRP(ptr), PACK(size, prev_alloc));
PUT(NEXT_PTR(ptr), NULL);
PUT(LAST_PTR(ptr), NULL);
coalesced(ptr); // 这个很重要,记得合并&插入链表
}
place
这个函数单独拿出来是我们的放置策略的问题。这里,参考了网上某位大牛的写法(如果涉及侵权,请联系我修改)。具体为什么要这样写,该文章中说得已经很清楚了。这种写法主要是为了对应binary-bal文件。这里简单概括一下。
其实核心思想就是将大的块放在右侧,小的块放在左侧,然后当大的块free掉之后,就能形成一个更大的块来存放。其实更多情况下这更像是一种针对数据造函数的思想,当然,如果数据更改或者是一些顺序更换,这样的写法就有时候反而会导致效率极度下降。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29static void* place(void* ptr, size_t size)
{
size_t all_size = GET_SIZE(HDRP(ptr)), res_size = all_size - size;
if (res_size < 16) {
OR(HDRP(NEXT_BLKP(ptr)), 0x2);
size = all_size;
PUT(HDRP(ptr), PACK(size, 0x3));
}
else if (size < 96) {
char* new_block = (char*)ptr + size;
PUT(HDRP(new_block), PACK(res_size, 0x2));
PUT(FTRP(new_block), PACK(res_size, 0x2));
PUT(NEXT_PTR(new_block), NULL);
PUT(LAST_PTR(new_block), NULL);
add_node(new_block, getSizeClass(res_size));
PUT(HDRP(ptr), PACK(size, 0x3));
} else {
char* new_block = (char*)ptr + res_size;
PUT(HDRP(ptr), PACK(res_size, 0x2));
PUT(FTRP(ptr), PACK(res_size, 0x2));
PUT(NEXT_PTR(ptr), NULL);
PUT(LAST_PTR(ptr), NULL);
add_node(ptr, getSizeClass(res_size));
PUT(HDRP(new_block), PACK(size, 0x3));
ptr = new_block;
OR(HDRP(NEXT_BLKP(ptr)), 0x2);
}
return ptr;
}
realloc
关于这个函数,是因为它有比较多的可以优化的地方。trace文件中的最后两个测试如果不采用一定的优化的话,会导致空间利用率很低,甚至Out of memory。
首先,如果realloc的size比之前还小,那么我们不需要进行拷贝,直接返回即可(或者可以考虑对当前块进行分割)
其次,如果下一块是一个空闲块的话,我们可以直接将其占用。这样的话可以很大程度上减少external fragmentation。充分地利用了空闲的块。(前一个块是空闲的话并没有什么作用。还是需要将内容复制过去,因此不讨论)
接着,如果下一个块恰好是堆顶,我们可以考虑直接拓展堆,这样的话就可以避免free和malloc,提高效率。
最后,实在没有办法的情况下,我们再考虑重新malloc一块内存,并且free掉原先的内存块。这里要注意一下malloc和free的顺序,如果直接换过来的话可能导致错误。(free的时候有可能会把predecessor和successor的位置清为NULL,这里具体要看前面的函数是怎么写的。总之要小心一点。)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43void *mm_realloc(void *ptr, size_t size)
{
if (size == 0) {
mm_free(ptr);
return NULL;
}
if (ptr == NULL)
return mm_malloc(size);
size_t oldBlockSize = GET_SIZE(HDRP(ptr));
size_t oldSize = oldBlockSize - WSIZE;
if (oldSize >= size) {
// 这里有另一种策略,如果realloc分配的内存过小,我们可以考虑对这个块进行分割,一定程度上提高了内存的利用率
return ptr;
} else {
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(ptr)));
size_t next_size = GET_SIZE(HDRP(NEXT_BLKP(ptr)));
// 下一块内存是空闲的,并且和当前块大小加起来足够用,则占用下一块内存
if (!next_alloc && next_size + oldSize >= size) {
delete_node(ptr + oldBlockSize, getSizeClass(next_size));
OR(HDRP(NEXT_BLKP(NEXT_BLKP(ptr))), 0x2);
PUT(HDRP(ptr), PACK(next_size + oldBlockSize, GET_PREV_ALLOC(HDRP(ptr)) | 0x1));
return ptr;
}
// 下一块内存刚好是堆的顶部,直接拓展即可。可以不用free后再malloc。
if (NEXT_BLKP(ptr) == start_pos) {
size_t newsize = ALIGN(size - oldSize);
if (mem_sbrk(newsize) == (void*)-1)
return NULL;
PUT(HDRP(ptr), PACK(oldBlockSize + newsize, GET_PREV_ALLOC(HDRP(ptr)) | 0x1));
start_pos += newsize;
PUT(HDRP(start_pos), PACK(0, 0x3));
return ptr;
}
void *newptr = mm_malloc(size);
if (newptr == NULL)
return NULL;
memcpy(newptr, ptr, oldSize);
mm_free(ptr);
return newptr;
}
}
something else
这个实验如果要拿到满分的话,可能还是得针对具体的数据设置恰当的自定义数据结构来完成。这里笔者实在无能为力了,只能简单提一下几种常见的思路吧。
首先还是说一下按照上述方法写,如果不出意外的话,应该是有95分以上的,但是我们会发现,这种写法存在这一些弊端。首先是一些讨论明显是针对测试数据而设计的,如果测试数据更改,那么整个程序的效率就会大打折扣。其次,我们采用将各个块根据大小分组的话会出现一些问题。比如random-bal文件中,alloc的数据大多数都很大(大于4096),或者实际应用中,多次申请相同大小的内存,它们将被放在同一个链表当中。如果分配后迟迟没有free的话,会导致链表越来越长,从而使得效率越来越低。这里有一种优化方式就是采用BST来进行维护。我们将所有大小相同的块组织成一个链表,BST中的每一个节点即为链表的表头,当某一个大小的块全部用完的时候,则将其从BST中删除,这样,插入和查找,搜索的效率均为O(log2n)。
具体的每个free块结构如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17struct block {
// 头部块
unsigned size_head:29;
unsigned flag_head:3;
// 链表的下一个节点和上一个节点
block* pred;
block* succ;
// 树的左儿子,右儿子和父亲
block* left;
block* right;
block* father;
payload...
// 尾部块
unsigned size_foot:29;
unsigned size_foot:3;
}
当然,采用BST的话,理论上我们运行的速度会快很多,然而,这还是有问题。BST并不能保证效率为O(log2n),当某些情况下,比如每一次分配的大小都恰好比上次多一点点,这样的话就会导致效率急剧下降,整个BST退化成了链表。为了解决这个办法,可以采用平衡树,这使得整体的各种操作的效率会更加趋近于O(log2n)。
至于空间效率方面的话,若要拿到满分,除了根据数据再进行一些特定的判断以外,笔者暂时想不到更好的办法了。如果你有一些更好的办法,请务必告诉我。
最后,如果有需要的话,欢迎到我的github上查看详细文件。
关于ptmalloc
既然我们前面已经讲述了如何自己手动模拟一个allocator,那么我们不妨来简单地看看真正的malloc函数究竟是怎么样的吧!
参考资料: https://blog.csdn.net/z_ryan/article/details/79950737
chunk
malloc中chunk的定义和我们的malloc lab颇为相似。具体定义在malloc.c文件中。其中,最后的两个next_size指针用于比较大的块中,当同一个大小的块较多时,线性遍历比较浪费时间,因此用next_size,指向下一个大小的块。
1 | struct malloc_chunk { |
同样的,共有两种不同类型的chunk,第一种是已被占用的chunk,另一种是空闲的chunk,在malloc.c中,结构如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34// allocated chunk
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk, in bytes |A|M|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User data starts here... .
. .
. (malloc_usable_size() bytes) .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| (size of chunk, but used for application data) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk, in bytes |A|0|1|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
// free chunk
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk, in bytes |A|0|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Forward pointer to next chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Back pointer to previous chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Unused space (may be 0 bytes long) .
. .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk, in bytes |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk, in bytes |A|0|0|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
其中,由于我们的块使用的是8字节对齐,因此,块的大小的最后3位一定是0。因此,我们同样可以把这三位利用起来。其中,最后一位P表示上一个块是否被占用,倒数第二位M表示该块是否来自于mmap函数,倒数第三位A表示当前块是否位于非主分配区。
分配区
在malloc中,共有两种分配区。第一种是MAIN_ARENA,即主分配区,初始时进行内存分配均在主分配区中。第二种是NON_MAIN_ARENA,即非主分配区。初始时仅有主分配区。分配区具体和线程相关,当某个线程想要使用malloc获取一段内存时,在有采用多线程的情况下,会先使用arena_get获得当前线程所在的分配区,并且,为该分配区加上互斥锁。该宏定义如下:
1 |
|
倘若从该分配区上没有分配到所需的内存时,尝试从其他分配区中获取内存。如果找不到一个未加锁的分配区,则使用mmap增加一个非主分配区,并在该分配区上分配内存。
bins
在malloc中,由于块之间是用链表串起来的,每一条链表我们称之为bin。其中,每个bin中的大小比较接近,并且bin中的块按照大小排序,当大小相同时,则按照使用是否最近刚使用过排序,类似于LRU。在malloc中,总共有128个bin,按照大小等因素分类,总共有以下四种bin:
- Fast bin
- Unsorted bin
- Small bin
- Large bin
各个相邻bin间的大小间隔如下:
64 bins of size 8
32 bins of size 64
16 bins of size 512
8 bins of size 4096
4 bins of size 32768
2 bins of size 262144
1 bin of size what’s left
Fast bin
fast bin中存放的是大小小于64B的chunk,用于处理程序在运行过程中申请的较小的内存空间。通常情况下,fast bin中即使两个块相邻也不会主动合并(合并后如果malloc又申请了一些较小的内存,那么需要再次进行分割,耗费时间)。各个bin存放的块的大小以8B递增,同时,每一个bin中块的大小相同,分配时直接从头部摘除,同理,free的时候直接连接在了头部,加快了分配的效率。
在分配时,malloc优先从fast bin中寻找大小恰当的块。
Unsorted bin
unsorted bin是bins的缓冲区,如同其名字所示,其中存放的bin的大小任意,并且也不需要按照大小顺序排序,当在small bin中找不到合适大小的块的时候,会在该bin中查找。当用户释放内存,或者fast bin合并后,或者发生了分割后剩下的块,会优先进入该bin。并且,查找后,把unsorted bin中的块放进对应的small bin或者large bin中。
Small bin
small bin中存放的是大小大于64B,小于512B的块,每个bin内的块大小相同,相邻的块之间大小相差8B。链表具体的各种操作和fast bin类似,不过两个相邻的块之间会发生合并,以减少碎片的产生。
Large bin
large bin中存放的是大小大于512B的块,其中,每个bin内块的大小不一,按照大小递减排序,大小相同则按照近期是否使用排序。分配时,完全遵循best fit,即满足大小要求的最小的块。分配后,会进行切割,剩下的块加入unsorted bin当中。
else
除了上面几种bin,还有一些比较特殊的块,不包含在任何一个bin当中。
- 大小超过128kb的块,将直接使用mmap函数。并且,所有M标记位为1的块,其他的标记位将被忽略,同时,这些块也不会进入到bin当中,当使用free函数时,这些块将直接通过unmmap还给操作系统
- top chunk。这是一个特殊的块,位于堆的顶部。当所有的bin中的块的大小都不满足要求时,将会使用这个chunk。(注意,这依然满足best fit,top chunk被视为无限大)。如果top chunk的大小仍然不够,则会根据所需的大小使用mmap或者sbrk来拓展。
malloc & free
当我们调用malloc函数时,首先调用的是__libc_malloc函数,该函数做一些判断处理的工作,最后,malloc的具体实现逻辑交由__int_malloc函数执行。具体步骤如下:
- 若是多线程,需要获取分配区的指针并上锁。否则跳过
- 计算所需的块的实际大小
- 如果所需的块大小小于fast bin的阈值,尝试从fast bin中获取。若获取失败,进入下一步。
- 若所需的块的大小位于small bin中,尝试从small bin中获取,若获取失败,进入第6步。若块的大小不位于small bin中,进入下一步。
- 调用malloc_consolidate函数,对fast bin进行拆除和合并,并扔进unsorted bin中。
- 进入循环,尝试从unsorted bin中获取,能获取到大于所需大小的,则进行切割并返回。同时,unsorted bin中大小位于small bin和large bin的块分别扔对应的bin中。
- 从large bin中按best fit查找,如果找到,则切割并返回。
- 从top chunk中获取,若top chunk 满足要求,则进行切割。若不满足要求,则扩容
总之,对于某一个特定的请求,执行的顺序大致为: fast bin -> small bin -> unsorted bin -> large bin -> top chunk -> extend_heap
当我们调用free函数时,整体的过程也是类似的。
- 首先,进行一些特殊判断后。如果该块属于mmap映射得到(M标志位),直接unmmap还给操作系统。否则,进入下一步。
- 获取分配区的指针。大小如果小于fast bin的阈值,直接放入其中。如果下一个chunk也是空闲,则触发合并操作,并扔入unsorted bin中。大小如果大于该阈值,则放入unsorted bin中,并且检查是否需要合并。
- 倘若当前块与top chunk相邻,则与top chunk合并。并且,对于主分配区,top chunk如果大于收缩阈值(128KB),则归还一部分给操作系统。
summary
这个实验难度真的比较大。很多东西都没有提供,要靠自己写。并且,对于这个实验来说,非常容易出现segment fault,并且调试难度很大。像笔者花在调试上面的时间真的很多,常常因为漏打了标记之类的出错,然后就一直检查不出来了,很花时间。当然,这个时间我觉得的话还是很值得的,起码锻炼了自己调试的能力。建议如果要做这个实验的话,可以试着每过一段时间就保存一下,尤其是正确通过测试的时候,把文件复制到别的地方,然后再继续做一些优化,这样出了问题我们还可以比较一下。
转眼之间这个已经是倒数第二个实验了,寒假也已经到了尾声。这个时候还是希望自己不要太焦躁,开学了,心态也要放好一点,这样才能更好地进步。