序
这是csapp系列的第八篇文章。具体题目请见官网。本文主要讲csapp中的proxy lab的一些问题以及解决办法。如果有什么写得不好的地方,欢迎联系我修改(右下角小图标点开即可对话,可能要稍微等一会)。
建议在开始实验以前,先把官方的资料看下。不然很可能不知道应该从哪里开始下手。当然,对实验的要求理解清楚之后,做起来还是很简单的(比起上一个实验的话)。
malloc lab
这个实验,要求我们完成一个网络代理,共分为三个部分:
A. 完成基础的代理的功能
B. 在上一步的基础上实现多线程
C. 在上一步的基础上添加缓存功能
具体实现时,可以在实验文件目录下,使用命令 ./driver.sh ,将自动进行测试。其中,第一部分40分,其余各15分,满分为70。但本实验的测试比较水,基本不需要考虑效率的问题,因此难度更降了一层。并且,csapp.c文件中将我们需要的大量的函数都进行了包装,直接调用即可。tiny.c文件也为我们写好了,在完成的时候,可以直接先复制过来。并且,后面B和C部分其实照着书打也就可以拿到满分了。
some notice
1. 在笔者的电脑上(arch linux系统),使用 ./driver.sh 命令时,发现报错了,显示 command not found 。解决的办法时安装需要的对应软件。在arch下,下载net-tools包即可解决,其他系统应该也是类似的。
2. 在bash中,可以使用命令 ./tiny 46350 & ,在46350端口运行server,并且在后台运行,方便调试。具体可能会用到的还有以下这些命令(具体作用不清楚的话可以查一下):
kill pid
fg jid
bg jid
jobs
3. 当完成某个部分时,可以使用命令 curl –proxy localhost:46351 localhost:46350 在本地对代理进行测试,并且可以在文件中输出一些信息,有利于调试。
4. 和服务器建立连接后,记得把文件描述符回收了,否则不仅占用资源,甚至会导致文件描述符不够用的情况。还有,要十分小心内存泄漏的问题,比如本实验中可能会用到malloc函数,别忘了回收。还有part B部分需要用到多线程,记得使用在子线程中使用pthread_detach(pthread_self()),保证线程资源能自动被系统回收。(也可以使用pthread_join()函数)。
实验正文
如果需要完整代码,请见github,仅供参考。本处仅讲几个比较重要的点。
http协议
想要完成本实验,必须对http协议的基本结构有一定的了解。因此,这里给出一个简单的http请求。
GET / HTTP/1.1
Host: localhost
Content-Length: 40
Connection: close<html>
…
</html>
如上。第一行为请求行,格式为”%s %s %s”,三个字符串间均有一个空格。其中,第一个字符串表示的是请求的类型(GET或HEAD或POST等);第二个字符串表示的是文件的位置,如果以‘/’字符结尾,则自动加上index.html(或home.html);第三个字符串表示的是版本,一般为“HTTP/1.1”,但这个实验要求我们向server发送信息时必须使用“HTTP/1.0”。
第二行开始是请求头,连续若干行,表示该请求相关的一些信息等。在本实验中,请求头需要有以下内容:
Connection: close
Proxy-Connection: close
用来表示服务端与用户端仅进行一次数据交换。在HTTP/1.0中,默认情况下是“Keep-Alive”。
请求头后有一个空行,这里要注意一下,该空行用来分离请求头与请求数据,不能省略。
随后的若干行均为请求数据,可以包含任意数据。
对于响应消息,其实和请求很相似。
HTTP/1.0 200 OK
Server: Tiny Web Server
Connection: close
Content-length: 115
Content-type: text/htmlWelcome to little_csd.net
Thanks fot you visited.
如上面为一个简单的相应信息。第一行为状态行,同样包含三个以单个空格隔开的字符串。第一个字符串表示协议,在这里是“HTTP/1.0”,第二个字符串表示的是状态码,第三个字符串表示的是状态消息,和状态码相对应。正常情况下,状态码和状态消息应该分别为”200”和“OK”。
第二行开始为消息报头,为客户端提供一些关于响应消息的信息,比如消息长度(仅含正文),消息类型等。
消息报头后紧接着又是一个空行,用来分隔。最后是响应正文。
有一点值得注意的是,http协议中,换行是由回车符‘\r’和换行符’\n’组成的,每一行结尾都需要添加这两个字符。
实现代理的基本思路
首先,我们必须明白代理是干什么用的。这样才能准确清楚我们要做什么。如同字面上的意思,代理起到一个类似中间商的作用。当我们利用代理访问某些网络资源的时候,我们客户端首先向代理发送信息,告诉它我们要访问的资源的位置。然后,代理就代替我们访问该资源(比如发送HTTP请求给服务端),服务端收到访问请求之后,将资源传回给了代理,代理接收后,又发送到我们客户端这边。这样我们就成功地间接访问到了该网络资源。这里以访问www.google.com 为例,用一张简单的图来说明一下。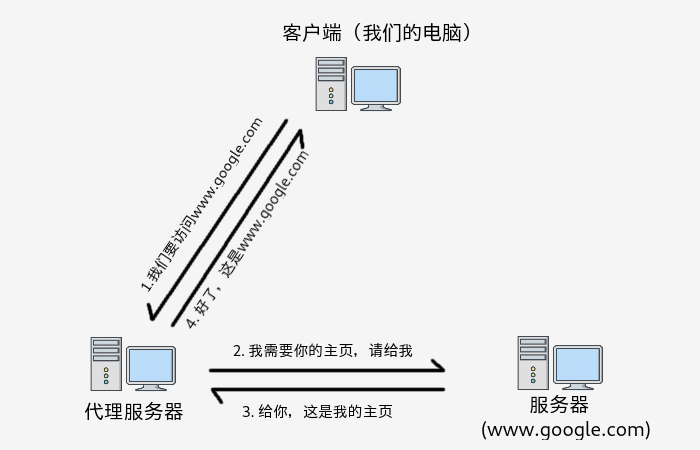
那么,为什么我们不能直接访问www.google.com 呢?答案显而易见了,www.google.com 被墙屏蔽了,在中国大陆境内访问不了(ipv4协议下)。因此,这就是代理的好处之一。通过访问另一台在墙外的主机,由它帮我们去访问一些被墙的网站,然后再返回给我们,这样我们就成功地间接访问到了我们想要的资源了。
当然,代理还有另一个重要的好处,它可以便于我们实现缓存。我们知道,如果我们每次都直接访问服务器,那么势必会给服务器带来巨大的压力,甚至导致服务器瘫痪。而我们如果代理的时候,它可以自动进行页面的缓存,这样下一次我们再访问同一个资源的时候,代理就不需要向服务器发送请求,直接从本地的缓存中拿出页面文件,然后送回给我们即可,这同时也提高了访问的效率。
好了,接下来我们考虑如何实现了。考虑到同样需要监听某个端口,我们可以直接复制tiny.c中的代码,进行适当的修改即可。(事实上我们只需要更改响应的逻辑)。
和客户端建立连接之后,我们需要读取客户端发送过来的请求,然后进行解析,得到客户端想要访问的主机,然后和对应的主机建立连接,发送HTTP请求(这里要十分注意HTTP请求的格式问题,容易出错)。然后,接收服务端的响应消息,原封不动地传回给客户端即可。1
2
3
4
5
6
7GET http://localhost:46350/ HTTP/1.1
Host: localhost:46350
User-Agent: curl/7.63.0
Accept: */*
Proxy-Connection: Keep-Alive
GET http://localhost:46350/ HTTP/1.1
上面展示的是,使用之前提到的curl命令后,代理收到的请求。我们只需要取请求头的url,获取主机(这里为localhost),端口号(这里为46350),文件位置为’/‘,然后我们只需要制作一个HTTP请求发给服务器即可。在我的proxy实现中,HTTP请求如下:1
2
3
4
5
6GET / HTTP/1.0
Host: localhost:46350
Connection: close
Proxy-Connection: close
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36
// 这个空行别漏了
添加多线程
前面说到了实现代理的基本思路,然而实际的服务器如果这样做的话,效率是很低的。我们一次只能处理一个访问请求,这样不合要求。因此,我们可以采用多线程的方法,通过多个线程一起工作来处理消息。当然,最简单的方法是,当接收到一个消息的时候,我们就创建一个线程,然后对消息进行处理。尽管这样就可以拿到该部分的满分了,但我们知道,创建一个线程,对系统来说时间和资源的开销是比较大的,每次接收到消息后就创建线程显然是不明智的,会导致时间上的浪费。因此,在这里我选择了采用预线程化的方法(类似与java中的线程池),加上书中提到的producer-consumer模式来完成。1
2
3
4
5
6
7
8
9void *doit(void *vargp)
{
Pthread_detach(pthread_self());
while (1) {
int connfd = sbuf_remove(&sbuf); // 从消息队列中移除某个消息并返回,这里会阻塞
forward(connfd); // 处理某个客户端的消息
Close(connfd);
}
}
我们选择在一开始就创建线程,然后让线程进入上述函数,这样它就进入了一个无限的循环当中。在sbuf_remove函数中,如果消息队列为空,线程将一直被阻塞,直到拿到消息。sbuf_t相关的一些函数如下,基本的写法其实和书里是一样的。1
2
3
4
5
6
7
8
9
10
11
12
13typedef struct {
int* buf; // 队列数组
int n; // 队列最大容量
int front,rear; // 用于构造队列
sem_t mutex;
sem_t slots;
sem_t items;
} sbuf_t;
void sbuf_init(sbuf_t *sp, int n);
void sbuf_deinit(sbuf_t *sp);
void sbuf_insert(sbuf_t *sp, int item);
int sbuf_remove(sbuf_t *sp);
添加缓存
对于一个比较完善的代理而已,缓存是不可或缺的。要实现缓存,我们需要把代理接收到的服务器的消息保存下来以及请求地址保存下来,然后,每次收到一个消息的时候,我们需要先在缓存中查找,如果在缓存中发现之前有过一个同样的请求,那么只需要直接从缓存中拿出,然后放回给客户端即可。
当然,这里又有另外一个问题,就是我们的缓存策略。正常情况下,比较恰当的缓存方法应该是LRU。当然,这里我偷懒了,采用的是FIFO,即先进先出策略。当缓存的页面数已满或者缓存的总大小超过了我们的设定的上限的时候,我们就将最远的一个缓存对象从缓存中移除。具体的写法见下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69typedef struct {
char cache[MAX_OBJECT_SIZE]; // 页面的内容
char dst[MAXLINE]; // 请求地址
int size; // 页面大小
} web_obj; // 缓存的对象
typedef struct {
web_obj* obj; // 缓存对象,这里是一个数组
int size_all; // 所有缓存对象页面内容的总大小
int n; // 缓存对象数的最大值
int objn_cnt; // 当前缓存的对象数
int read_cnt; // 用于
int front, rear; // 用于队列的构造
sem_t mutex; // web_cache访问锁
sem_t write; // 写入的锁,这里采用了读者优先模式
} web_cache;
void cache_init(web_cache *cache, int n);
void cache_remove(web_cache *cache, int pos);
char* cache_find(web_cache *cache, char* dst)
{
// 这里需要加锁操作
int i, n = cache->n;
int l = (cache->front+1) % n, len = cache->objn_cnt;
char *ans;
for (i = 0; i < len; i++)
{
web_obj *obj = cache->obj + l;
if (!strcmp(obj->dst, dst)) {
int size = obj->size;
ans = Malloc(size); // 重新开辟一段存储空间
strcpy(ans, obj->cache);
break;
}
l = (l + 1) % n;
}
// 这里将锁还回
if (i == len) return NULL;
else return ans;
}
void cache_put(web_cache *wcache, char *dst, char *cache)
{
P(&wcache->write);
int cnt = wcache->objn_cnt, n = wcache->n;
if (cnt == n) {
int pos = (wcache->front+1) % n;
cache_remove(wcache, pos);
}
int pos = (++wcache->rear) % n, size = strlen(cache);
web_obj *obj = wcache->obj + pos;
strcpy(obj->dst, dst);
strcpy(obj->cache, cache);
obj->size = size;
wcache->size_all += size;
wcache->objn_cnt++;
while(wcache->size_all > MAX_CACHE_SIZE) {
int pos = (wcache->front+1) % n;
cache_remove(wcache, pos);
}
V(&wcache->write);
}
整个缓存的模型上面已经展示得很清楚了,但有几个需要十分小心的点。第一个是find的时候,由于有加锁的存在,我们可以保证在当前某线程在搜索的时候,所有缓存对象不会因写入而发生更改,并且,统一时间最多只能有一个线程在遍历缓存对象。但是,当缓存命中的时候,我们需要返回什么?如果直接将缓存对象的指针返回,看似是没有问题的,但该函数如果在还锁之后,线程突然被挂起,然后有另一个线程执行了写操作,恰好将我们返回的那个缓存对象覆盖了。这个时候之前的那个线程重新执行,它返回的指针指向的对象这个时候其实就已经发生变化了。这个一定要理解清楚。
因此,我们选择了将重新开辟一段存储空间,将缓存对象的页面内容放在上面,这个时候,正常情况下,这段空间的内容就不会被其他线程修改了,于是,页面的内容可以正确地返回给了调用它的函数。但是这里又有另一个问题,我们开辟了一段存储空间,同时也需要对其进行回收,因此这就要求了调用cache_find()的函数,在获得了页面对象并使用了之后,需要将该段内容回收。
summary
终于又到了总结的时候了。对这个实验,尽管难度不大,但我们还是可以从其中学会很多东西。比如HTTP请求和响应的一些格式问题,我们能从应用层了解到网络访问是如何实现的。并且,我们也了解到了多线程技术,正确地使用的情况下,可以很大程度上提高程序的效率,并且充分利用了多核CPU的计算能力。当然,这也同时带来了一系列的问题,比如多线程之间的竞争,处理不当会导致程序每次执行的结果都不一样。以及多线程之间共享对象的读写,我们引用了锁的概念,这又带来了一系列新的问题,当一个线程一直持有锁,会导致其他线程被饿死(starvation),又或者一个线程持有锁的同时又被挂起,导致陷入了死锁(dead lock),这一系列都是会对我们的程序造成很大影响的错误。由此,线程安全对与一个编程者而言,重要性不言而喻。
最后,还是要来对整个系列做一个小总结的。从去年12月初开始,到今天2月底为止,历时两个多月,终于把这CS:APP3e看完了,并且完成了所有的实验,大部分也都写了认真地写完了相应的博客。怎么说呢,这段时间对我来说收获确实还是很大的,从一个对系统底层几乎毫不了解的小萌新,到现在对CPU,程序等有了一个简单的认识,这一步的跨越还是很大的,很感谢推荐这本书给我的师兄们。
这个系列到今天为止应该也就结束了。很意外的是,基本上自己还是勉勉强强完成了当初给自己立下的flag。接下来的一段时间应该博客就不会有更新了,可能下一个考虑学一下计网吧(如果有可能的话,会做一下上面的实验并写几篇博客)。
皆さん、さよなら