序
这篇系列主要是Computer Networking A Top-Down Approach的一些笔记和心得之类的东西。不过不知到能不能坚持下去。这篇文章主要是运输层相关的一些知识点的笔记。希望能加深自己对网络这块的理解。在经典的五层协议模型中,运输层位于应用层和网络层中间,为应用程序的进程之间的通信起着重要的作用。其中,我们重点研究的对象是运输层协议,包括TCP和UDP。
socket
socket是不同端系统间进程通信的基本单位,是操作系统提供的进程间通讯机制。
主要方法有(以python为例):
创建socket:
socket = socket(AF_INET, SOCK_STREAM),其中,第一个参数指定了IPv4协议,第二个参数指定了TCP协议。同样的,UDP协议的第二个参数为SOCK_DGRAM。函数返回建立的socket的文件描述符
发送或接收数据:
socket.recv() (recv方法会阻塞)
socket.send()
绑定某个端口:
socket.bind(),若使用UDP协议发送数据,无需绑定端口
Client:
socket.connect() ,与某个socket建立连接,具体建立链接的过程由内核实现(如三次握手)
状态序列如下: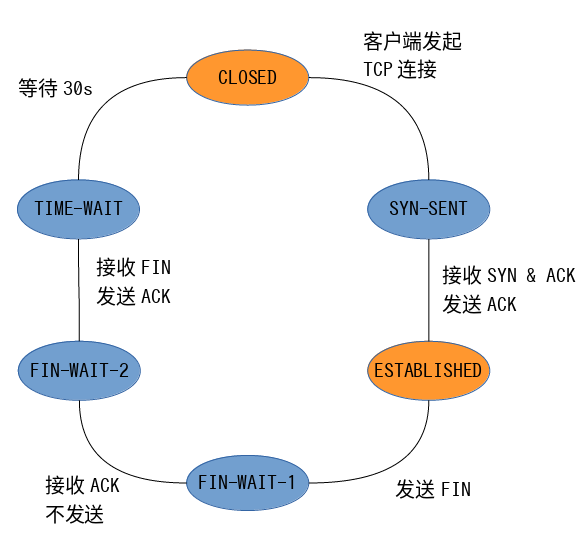
Server:
socket.listen() ,作用是通知内核,将该socket由主动套接字转化为被动套接字,处于LISTEN状态,此方法不阻塞。同时,内核为每个监听套接字两个队列:
未完成连接队列:收到了SYN,等待第三次握手,此时,socket的状态为SYN_RCVD。
已完成连接队列:三次握手过后,已建立连接,此时,socket状态为ESTABLISHED。
socket.accept():内核从已完成连接的队列中取出socket,并为之分配相应的内存和文件描述符。如果已完成连接的队列为空,则进程被挂起,直到队列非空。
状态序列如下: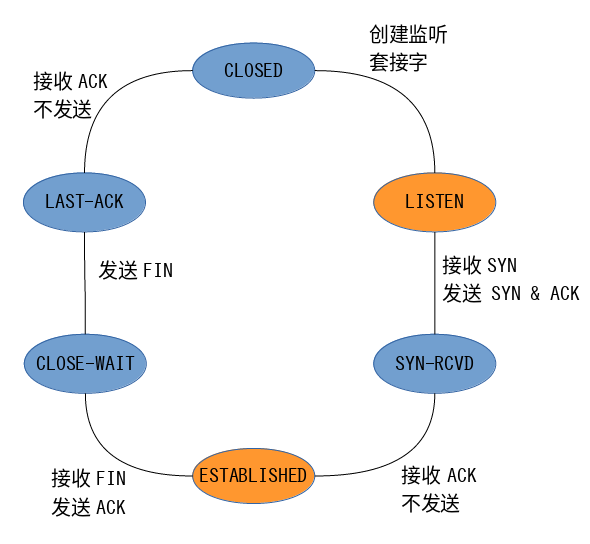
Python下使用TCP协议实现简单的客户端和服务端:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// Client
clientSocket = socket(AF_INET, SOCK_STREAM)
clientSocket.connect((serverName, serverPort))
sentence = input('Input lowercase sentence:')
clientSocket.send(sentence.encode())
modifiedMessage = clientSocket.recv(1024)
print('From Server: ', modifiedMessage.decode())
clientSocket.close()
// Server
serverSocket = socket(AF_INET, SOCK_STREAM)
serverSocket.bind(('', serverPort))
serverSocket.listen(1)
print('The server is ready to receive')
while True:
connectionSocket, addr = serverSocket.accept()
sentence = connectionSocket.recv(1024).decode()
capitalizedSentenced = sentence.upper()
connectionSocket.send(capitalizedSentenced.encode())
connectionSocket.close()
UDP协议
UDP协议和TCP相比,有以下特点:
- UDP是一种无连接协议,端系统间不需要进行连接就可进行通信。因此,UDP时延较小。
- UDP首部仅8字节,远远小于TCP。甚至我们可以在应用层基于UDP设计自己的协议。
- UDP是一种不可靠的协议,它不能保证数据的按序,准确交付。
以下是UDP报文段的结构: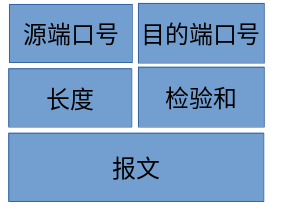
TCP协议
TCP协议具有以下特点:
- 面向连接。端系统的进程在相互通信前,需要先进行三次握手,此后才能正式开始连接。(注意:TCP是一种抽象意义上的连接,其状态仅仅保存在两个对应的端系统当中,中间的网络元素不负责维持该连接状态)
- TCP连接提供的是全双工服务,即两个端系统直接可以直接相互发送信息。
- TCP是可靠的运输协议,能保证数据的准确交付,但不能保证数据的按序,按时交付。
以下是TCP报文段的结构: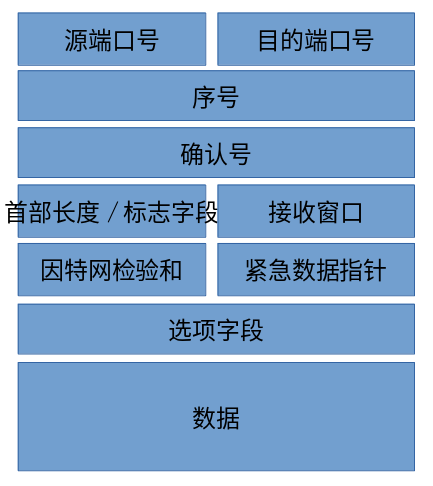
超时时间的估计
TCP通过超时/重传机制来处理报文段丢失问题。超时长度的限定比较复杂,具体公式如下:
我们可以通过每一次某报文段从发出到收到并确认所需的时间来估计,并且,直觉告诉我们,越近的一次RTT对和下一次传输的RTT的关系应该是比较紧密的,因此,我们可以选择维护一个EstimatedRTT值,每当获得一个新的SampleRTT时,则对其进行更新,具体规则如下:
EstimatedRTT = (1 - a) * EstimatedRTT + a * SampleRTT
这种平均被称为指数加权移动平均,能比较好的估计出下一次RTT,其中a的推荐值为0.125。但是,我们超时间隔肯定是要比这个要大一些的。并且,为了尽量传输时延,同时,也要尽量减少不必要的重传,我们可以借助偏离值来估算。具体公式如下:
DevRTT = (1 - b) * DevRTT + b * |EstimatedRTT - SampleRTT|
其中,b的推荐值为0.25。这样,我们可以大概估算出近几个包我们的估计值的误差大小,当这个误差比较大时,说明网络情况不是很好,有时发生了阻塞,这个时候我们应该稍微增大超时间隔,以适应网络的波动。于是,我们最终得到的超时重传时间计算公式如下:
TimeoutInterval = EstimatedRTT + 4 * DevRTT
另外,在发生超时事件后,TCP将不再为超时的包计算RTT,同时,超时间隔加倍,这就提供了某种形式上的拥塞控制,当网络拥塞发生时,TCP会通过阻塞客户端发包的速率来避免加剧拥塞。
由于有时候超时周期比较长,一个报文段丢失后,要等很久才能重传,而后面的包由于窗口大小的限制无法发送,这就导致了时间的浪费。当接收到大于3个以上的冗余ACK的时候,说明接收方在该ACK后的一个包缺失,这时就会触发快速重传。
TCP拥塞控制算法
TCP采用的是拥塞窗口(cwnd)来限制发送方向其连接发送流量的。具体是,在发送方中,未被确认的数据量不会超过cwnd与rwnd中的最小值,即:
LastByteSent - LastByteAcked <= min {cwnd, rwnd}
我们知道,TCP仅存在与建立连接的两个端系统上,那么,TCP是如何检测网络拥塞的发生呢?答案是RTT。当发生丢包事件时,即告诉发送方:网络可能发生了拥塞,于是TCP就降低了发送速率。而当收到一个非冗余的ACK时,即告诉了发送方:当前网络通畅,可以继续发送。这是TCP拥塞控制基础。
慢启动
当一条TCP连接开始时,cwnd通常设置为一个较小值(一个MSS)。当第一个发送的包确认到达时,cwnd的值加上一个MSS,于是,第二次发送了两个报文段,同理,当两个报文段都收到时,第三次发送四个报文段,依次类推。当收到一个超时指示的丢包事件时,TCP发送方将cwnd置为1,并重新开始慢启动过程,并且设置慢启动阈值(ssthresh)记为cwnd/2。此后,若当前的cwnd达到或超过了ssthresh,则不再翻倍,而是进入拥塞避免状态。
拥塞避免
为了避免拥塞,在该状态下,每个RTT内(不是每次收到ACK),cwnd的值只增加一个MSS。TCP发送速率呈较稳定的增长状态。当出现超时指示的丢包事件时,同样的ssthresh被更新为cwnd的一半,同时,cwnd被记为一个MSS。当然,如果出现3个冗余ACK指示的丢包事件时,TCP将cwnd的值减半(为了更好的测量结果,cwnd还应该再加上3个MSS),更新ssthresh的值,同时进入快速恢复状态。
快速恢复
注意,该状态对TCP来说不是必备的。
在快速回复中,对于造成进入快速恢复状态的ACK,每当收到一个冗余的该ACK时,cwnd增加一个MSS,最终,当丢失报文段的ACK到达时,TCP在降低cwnd后进入拥塞避免状态。同时,如果出现了超时事件,则进入慢启动状态。
如下为一个TCP拥塞窗口演化实例: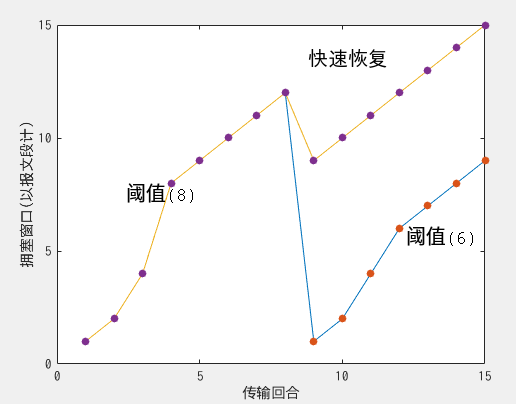
小结
从上面的拥塞窗口演化图中,我们可以看到,当进入快速回复状态,很明显传输的效率要高一些,当然,我们也发现,如果网络稳定的话,拥塞窗口将呈现一个锯齿状的状态。当今已经有很多算法可以优化这一点,避免了锯齿状的发生。由于慢启动的原因,如果RTT本身就很大的话,这将很大程度上影响用户的体验。对此,有一个解决方式是,部署一个临近用户的前端服务器,在该服务器上利用TCP分岔来分裂TCP连接。即用户向该服务器发送请求,该服务器进行以一个很大的窗口向数据中心维护一条TCP连接,这样的话,响应时间能从大概4RTT降低到RTT。
Some Detail
1. 端口并不是一个物理层面的概念,而是一个抽象概念。它仅仅是协议栈中的两个字节。
2. TCP和UDP协议可以“监听”同一个端口,两者之间互不干扰。主机在进行多路分解时,是根据{ 协议, 目的端口号, 目的地址, 源端口号, 源地址 }来判断数据是属于哪一个套接字的。
3. 通常情况下,对于某一个特定的协议而言,一个端口号只能对应一个socket,但有例外。比如在创建socket并调用listen方法后,再fork出子进程,此时由于父子进程之间共享了文件描述符,监听的是同一个socket。在linux3.9(不是很确定)以后,当有连接请求时,内核自动选择唤醒某个进程对请求进行处理。在此之前则会唤醒所有进程,并让其中的某一个处理事件。